CAS 기반 동시성 처리
어느 날 자바로 알고리즘 문제를 풀다가 재귀 함수를 구현했는데 스레드가 스택을 타고 올라오자 Integer 값 되돌아가는 것을 발견했다. 이 현상은 Integer가 불변 객체라서 발생한다.
생각은 “가변 객체 AtomicInteger를 쓰면 해결은 되겠네”로 이어졌고 바꿨을 때 성능이 어떻게 변할지 생각해봤다. 그런데 둘의 성능 차이는 원자적 연산의 유무에 있으니까 그걸 어떻게 처리하는지 이해해야 했다.
자바의 AtomicInteger는 CAS 기반으로 read-modify-write를 원자적으로 처리한다. 이 CAS 기반이란 뭘 말하는 걸까?
CAS (Compare-And-Swap) 기반이란?
CAS는 CPU 하드웨어 수준에서 제공하는 원자적 명령어를 기반으로 한다. 락(LOCK)을 사용하지 않고도 동시성 문제를 해결할 수 있는 핵심 메커니즘이다.
CAS의 동작 원리
CAS는 세 개의 피연산자를 받는다:
- 메모리 위치(V): 값을 변경할 주소
- 예상 값(A): 현재 그 위치에 있을 거라고 기대하는 값
- 새 값(B): 바꾸고 싶은 값
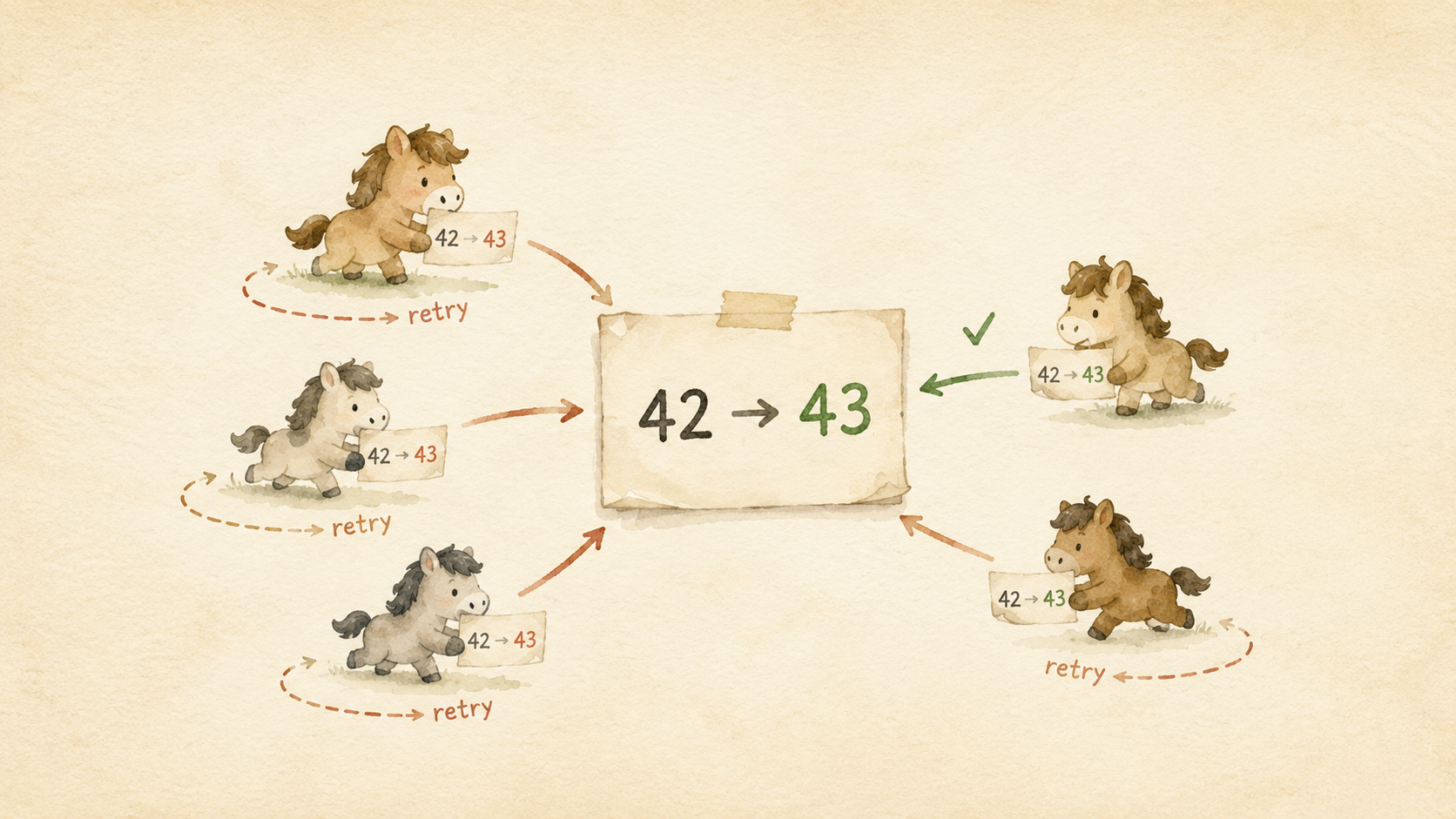
동작은 단순하다. “메모리 위치 V의 현재 값이 A와 같다면 B로 바꾸고, 다르면 아무것도 하지 않는다” 를 하나의 원자적 명령어로 수행한다. 비교와 교체 사이에 다른 스레드가 끼어들 수 없다는 게 핵심이다.
1
2
3
4
5
6
boolean CAS(V, A, B):
if (*V == A):
*V = B
return true
else:
return false
“어떤 기반인가?” - CPU 명령어
CAS는 소프트웨어 알고리즘이 아니라 CPU 명령어 자체이다. 아키텍처별로 이름이 다르다:
- x86/x64:
CMPXCHG명령어 (보통LOCK CMPXCHG형태로, LOCK 프리픽스가 캐시 라인을 잠가 다른 코어의 접근을 막음) - ARM:
LDREX/STREX또는 ARMv8 이후CAS명령어 - PowerPC:
LWARX/STWCX쌍
JVM은 이걸 인트린식(intrinsic)으로 처리한다. AtomicInteger.compareAndSet()을 호출하면 JIT 컴파일러가 일반적인 메서드 호출로 컴파일하지 않고, 위의 CPU 명령어로 직접 치환해버린다. 그래서 오버헤드가 무척 작다.
내부적으로는 Unsafe.compareAndSwapInt()(Java 9+ 에서는 VarHandle.compareAndSet())을 거쳐 네이티브 수준에서 CPU 명령어 수준으로 내려간다.
AtomicInteger의 increment 구현
incrementAndGet()이 어떻게 동작하는지 보면 이해가 쉽다:
1
2
3
4
5
6
7
8
public final int incrementAndGet() {
int prev, next;
do {
prev = get(); // 1. 현재 값 읽기
next = prev + 1; // 2. 새 값 계산
} while (!compareAndSet(prev, next)); // 3. CAS로 교체 시도
return next;
}
핵심은 재시도 루프이다. 만약 prev를 읽은 직후 다른 스레드가 값을 바꿔버리면, compareAndSet()은 false를 반환하고 루프가 다시 돈다. 누군가 값을 변경했다는 사실을 “예상 값과 다르다”는 것으로 감지하는 것이다.
Lock 기반과의 차이
| Lock 기반(synchronized) | CAS 기반 | |
|---|---|---|
| 방식 | 비관적(선점 후 작업) | 낙관적(시도 후 검증) |
| 실패 시 | 블로킹(대기) | 재시도(스핀) |
| 컨텍스트 스위칭 | 발생 | 없음 |
| 데드락 | 가능 | 불가능 |
낮은 경합(low contention)에서는 CAS가 압도적으로 빠르다. 락 획득/해제 비용도 없고 스레드가 잠들었다 깨어나는 컨텍스트 스위칭 비용도 없으니까.
CAS의 한계
CAS도 만능은 아니다. 알아두면 좋은 두 가지 약점이 있다.
경합이 심해지면 성능이 떨어진다. 여러 스레드가 같은 변수를 두고 계속 부딪히면 CAS 실패 ➔ 재시도가 반복되면서 CPU만 태우는 상황이 생긴다. 이걸 완화하려고 Java 8에서 LongAdder가 추가됐다. 내부적으로 여러 셀(cell)에 분산 저장하고 읽을 때 합치는 방식이라, 높은 경합 환경에서 AtomicLong 보다 훨씬 성능이 좋다. 카운터처럼 쓰기가 많고 읽기가 가끔인 워크로드라면 LongAdder를 고려해볼만 하다.
ABA 문제도 유명하다. 값이 A ➔ B ➔ A 로 바뀌었을 때, CAS는 “여전히 A네” 라고 판단해서 변경이 없었던 것처럼 처리해버린다. 단순 카운터에서는 문제가 없지만, 포인터나 참조를 다룰 때는 위험할 수 있다. 이걸 해결하려고 AtomicStampedReference(버전 스탬프 포함)나 AtomicMarkableReference를 제공한다.
닫는 말
여기까지 자바 Atomic 타입의 CAS 기반 원자적 처리 방법을 살펴봤다. 하지만 한 가지 의문이 남는다. 멀티코어 환경에서 각 CPU 코어는 자신만의 캐시(L1, L2)를 가지고 있는데, CAS는 어떻게 “현재 메모리의 값”을 정확히 비교할 수 있을까? 한 코어가 변경한 값이 다른 코어의 캐시에는 아직 반영되지 않았을 수도 있는데 말이다.
여기서 등장하는 것이 캐시 일관성 프로토콜(MESI)과 메모리 배리어다. 이 부분은 다음 글에서 이어서 다뤄보려 한다.