에이전트의 기억이 충분한데도 결과가 나빠지는 이유와 해결책
이전 글에서 세션 경계 문제를 해결하는 방법을 이야기했다. 그런데 곧 다른 병목을 마주했다. 그건 컨텍스트 윈도우에 여유가 남아 있는데도 에이전트가 흐려지는 현상이었다. 이전에 명시했던 규칙을 30분 뒤에 무시하고, 도구를 늘렸더니 답이 더 두루뭉술해지고, 같은 질문에 두 번째 답이 첫 번째보다 흐려졌다.
Anthropic은 이 현상을 컨텍스트 부패(context rot)라 부른다. 10분짜리 회의와 3시간짜리 회의에서 우리가 같은 밀도로 발언을 기억하지 못하는 것과 같다. 왜 이런 일이 일어나는지는 다음 장에서 짚는다. 일단 이 글의 출발점은, 컨텍스트 윈도우에 여유가 있어도 그 안에서 무엇이 살아남고 무엇이 묻히는지가 따로 결정된다는 사실이다.
그렇다면 고민되는 부분은 “무엇을 더 넣을까”가 아니라 “무엇을 넣지 않을 것인가”가 된다. 이전 글이 세션 사이에 무엇을 파일로 남길지를 다뤘다면, 이 글은 세션 안에서 무엇을 컨텍스트 윈도우에 들이지 않을지를 다룬다. Anthropic은 이 골라내는 기술을 context engineering이라 부른다.
1. Summary — context engineering이 다루는 것
원문은 context를 LLM이 다음 토큰을 뽑을 때 보는 토큰 전체로 정의한다. System prompt, 사용자 메시지, 모델이 여태 한 답변, 호출된 도구의 정의, 그 도구들이 돌려준 응답, 그리고 모델이 외부에서 끌어온 모든 자료. 이 모든 것이 한 추론 시점에 모델이 보는 컨텍스트다. Context engineering은 이 컨텍스트를 큐레이션하는 작업이다. 원문은 이것을 prompt engineering의 자연스러운 진화로 본다. 한 번에 잘 짜인 프롬프트 하나를 쓰는 일이, 매 추론마다 어떤 토큰들이 모델 앞에 놓일지를 결정하는 일로 진화했다고 말이다.
큐레이션(Curation)은 방대한 정보나 콘텐츠 속에서 필요한 것만 선별하고 분류하여, 새로운 가치를 부여해 제공하는 일을 뜻한다.
큐레이션이라는 단어가 무겁게 들릴 수 있는데, 이 작업이 필요한 이유는 의외로 단순하다. 모델이 한 번에 처리할 수 있는 집중력이 유한하기 때문이다. 원문은 이를 어텐션 예산(attention budget)이라 부른다. 사람이 회의가 길어질수록 발언 하나하나에 쓰는 집중력이 줄어들 듯, 모델도 컨텍스트에 새 토큰이 들어올 때마다 이 예산을 조금씩 깎아 쓴다. 도입부에서 말한 컨텍스트 부패가 이 예산이 바닥나는 현상이다.
왜 예산이 유한한가에 대한 답은 모델 아키텍처에 있다. 원문은 세 가지 근거를 든다.
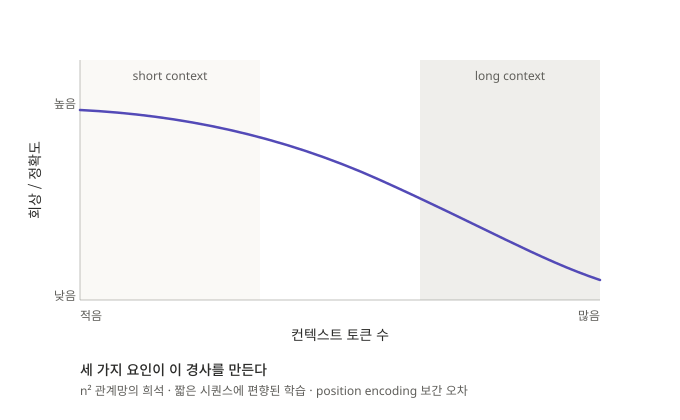
- Transformer는 모든 토큰이 다른 모든 토큰을 참조하는 구조라 토큰이 n개면 관계가 n²개로 늘어난다. 컨텍스트가 길어질수록 이 관계망이 얇게 펴진다.
- 모델의 학습 데이터는 짧은 시퀀스가 더 흔하므로, 모델은 짧은 컨텍스트에 훨씬 많은 경험을 가진 채 긴 컨텍스트를 처음 마주한다.
- Position encoding을 길이에 맞게 보간(interpolation)하는 트릭으로 긴 시퀀스를 다루지만, 이 보간은 위치 정보의 정확도를 약간씩 떨어뜨린다.
세 요인이 합쳐져 절벽 같은 성능 급감소가 아닌 완만한 경사면을 만든다. 컨텍스트가 길어진다고 모델이 갑자기 멍청해지는 것은 아니지만, 정확도와 회상 능력은 조용히 깎인다.
여기서 좋은 컨텍스트의 원리가 따라 나온다. 원하는 동작을 끌어내는 최소한의 고신호 토큰. 원문은 정적인 컨텍스트가 큐레이션되는 곳을 세 층으로 짚는다.
- 지시(system prompt) — 너무 빡빡한 if-else도, 너무 추상적인 원칙도 아닌 적정 고도(right altitude)에서 쓴다.
- 도구(tools) — 기능이 겹치거나 어떤 도구를 골라야 할지 모호해지는 bloated tool sets를 피하고, 잘 설계된 코드베이스의 함수처럼 자기완결적이고 명확하게 만든다.
- 예시(few-shot examples) — 가능한 모든 엣지 케이스를 나열하기보다, 기대 동작을 잘 그려내는 전형적(canonical) 예시 몇 개를 고른다.
세 층에 적용할 공통 원리는 같다. 더 많이 넣는 게 아니라, 신호가 약한 것을 덜어내는 쪽이다.
여기까지가 한 세션 안에 컨텍스트를 처음 어떻게 채울지에 대한 이야기다. 그런데 세션이 길어져 토큰이 컨텍스트 윈도우를 넘어서기 시작하면 이 정적 큐레이션만으로는 부족해진다. 원문은 이 지점에서 세 가지 long-horizon 전략을 꺼내는데, 그건 3장에서 다룬다.
2. 원문이 말하지 않은 것들
2.1. 세 전략이 사실 하나인 이유
원문은 long-horizon 전략을 셋으로 나눠 차례로 소개한다.
- Compaction은 컨텍스트 윈도우가 한계에 가까워지면 지금까지의 대화를 모델이 요약하게 하고 새 윈도우를 그 요약으로 다시 연다.
- Structured note-taking은 에이전트가 작업 중에 핵심 진행 상태를 외부 파일에 적어두고, 필요할 때 다시 읽어 들인다.
- Sub-agent는 깊은 탐색이 필요한 일을 별도의 깨끗한 컨텍스트 윈도우에서 돌리고, 끝나면 짧은 요약만 메인 에이전트로 돌려보낸다.
원문은 셋을 나란히 놓고 “task 성격에 따라 골라 쓰라”고 한다 — 대화 흐름이 중요하면 compaction, 마일스톤이 또렷한 반복 작업이면 note-taking, 병렬 탐색이 가치 있는 연구라면 sub-agent.
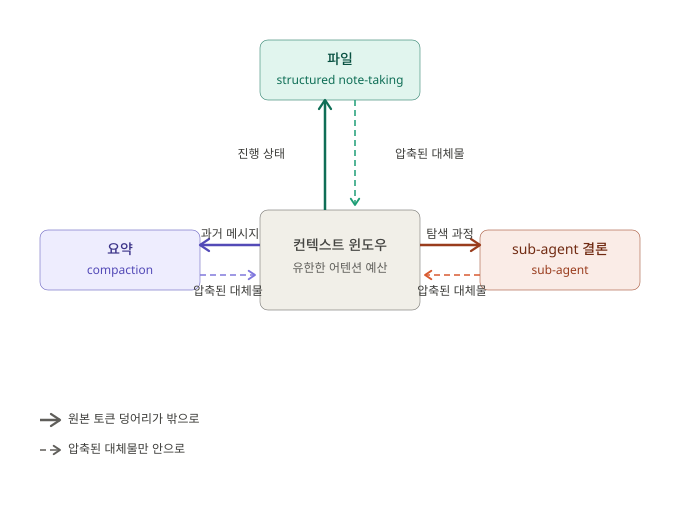
처음 읽으면 셋이 다른 기법처럼 보인다. 그런데 한 발짝 떨어져서 보면 셋 다 같은 한 가지 동작을 한다. 어텐션 예산을 잡아먹고 있는 토큰 덩어리를 컨텍스트 밖으로 꺼내고, 필요할 때 압축된 형태로 다시 들여온다. 차이는 빼내는 대상 하나뿐이다.
- Compaction이 빼내는 것은 과거 메시지다. 모델 자신이 자기 대화를 요약하게 하고 원본 메시지 히스토리는 버리고 요약만 새 윈도우에 들여놓는다.
- Note-taking이 빼내는 것은 진행 상태다. “지금까지 한 일 / 다음에 할 일”을 파일에 적어 컨텍스트 밖에 두고, 그 파일이 필요한 시점에 모델이 직접 읽는다.
- Sub-agent가 빼내는 것은 탐색 과정이다. 수만 토큰이 들 수도 있는 깊은 탐색을 별도 컨텍스트에서 끝내버리고, 메인 에이전트는 그 결과의 1~2천 토큰짜리 요약만 받는다.
세 가지 모두 원본 토큰은 컨텍스트에 두지 않고 — 요약이든 파일이든 sub-agent의 결론이든 — 압축된 대체물만 컨텍스트에 들인다. 백엔드식으로 말하면 셋은 같은 인터페이스의 세 가지 구현이다. 인터페이스가 정의하는 동작은 하나 — 토큰 덩어리를 컨텍스트 밖 어딘가에 두고, 컨텍스트 안에는 그걸 대신할 짧은 무언가만 남긴다. 구현체끼리 다른 점은 어떤 종류의 토큰을 밖으로 빼내는가 하나뿐이다.
원문이 셋을 나란히 놓고 “task에 따라 골라 쓰라”고 하는 건 좋은 조언이다. 하지만 그 조언 밑에 깔린 공통 메커니즘은 원문이 명시하지 않는다. 그래서 셋이 별개의 트릭처럼 읽히고, 어떤 task에 어떤 걸 쓸지를 경험적으로 매칭하는 꼴이 되기 쉽다. 공통 메커니즘을 한 번 짚어두면 매칭의 기준이 달라진다 — “이 task에서 컨텍스트를 잡아먹는 토큰 덩어리는 무엇이고, 그걸 어디로 빼낼 수 있는가”를 먼저 묻게 된다. 빼낼 대상이 정해지면 어느 전략이 맞는지는 거의 자동으로 따라온다. 과거 메시지면 compaction, 진행 상태면 note-taking, 탐색 과정이면 sub-agent.
2.2. Tool 정의는 호출되지 않아도 비용을 낸다
도구(tool)는 에이전트가 매 턴 “호출할지 말지” 고를 수 있는 기능 단위 — 파일 읽기, API 호출, 검색 실행 같은 것들이다. 이 절에서 따질 것은 도구가 하는 일이 아니라, 모델이 매 턴 고르기 위해 “도구가 어떻게 소개되어 있어야 하는가?” 이다.
원문은 “bloated tool sets는 컨텍스트를 낭비한다”라고 한 줄로 짚고 지나간다. 아마 이 문장은 가볍게 읽히고 넘겨질 것이다. 백엔드 개발자의 직관에서 사용되지 않는 dependency는 별 문제는 아니기 때문이다. build.gradle에 라이브러리를 하나 더 적어두면 빌드 산출물이 약간 무거워지고 빌드 시간이 약간 늘어날 뿐, 우리가 그 라이브러리를 호출하지 않는 한 런타임 성능은 깎이지 않는다. 비용은 사용할 때 발생한다 — 우리는 이 직관에 익숙하다.
그런데 에이전트의 도구 집합은 다르다. MCP 서버 열 개를 붙여 도구 쉰 개를 등록한 순간, 우리가 그중 하나도 호출하지 않은 턴에서도 쉰 개의 정의 전부가 시스템 프롬프트에 실려 모델 앞에 놓인다. 어텐션 예산은 호출 빈도가 아니라 존재 자체에 비례해서 깎인다. 백엔드의 dependency가 디스크에 잠자고 있는 자원이라면, tool 정의는 매 턴 깨어나 자기 자리를 차지하는 자원이다.
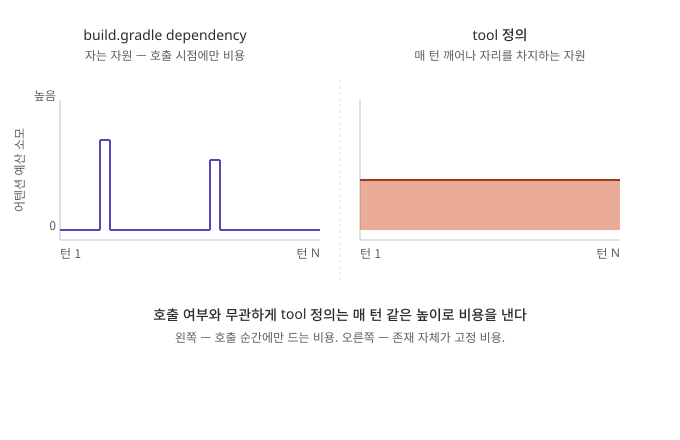
왜 매 턴일까? LLM 추론은 상태가 없기 때문이다. 직전 턴에 read_file을 골랐으니 다음 턴에는 그 도구의 시그니처를 빼도 된다 — 같은 최적화가 통하지 않는다. 모델은 매 턴 “어떤 도구를 호출할 수 있는가” 라는 선택지의 전체 집합을 새로 받아야 다음 행동을 정한다. 정의 한 줄 한 줄이 호출 가능성으로서 거기 있어야 의미가 있는 자원이다. 그러니 도구를 추가하는 일은 “필요할 때만 발동되는 기능을 하나 더 얹는” 일이 아니라, 모든 후속 추론의 시야 한구석을 영구적으로 차지하는 토큰 덩어리를 등록하는 일에 가깝다.
부피 감각도 직관과 어긋난다. 잘 쓰여진 도구 정의 하나는 이름·설명·파라미터 스키마·타입·예시까지 갖추면 어렵지 않게 수백 토큰이 된다. MCP 서버 두세 개만 붙여도 시스템 프롬프트 상단에 수천에서 수만 토큰이 고정 고지서로 매겨진다. 이 고지서는 사용자 메시지가 길든 짧든, 호출이 일어나든 안 일어나든 매 턴 같은 액수로 청구된다. 1장에서 본 어텐션 예산의 경사면 위에서, 이만큼은 대화가 시작되기도 전에 이미 깎여 있는 양이다.
여기까지 보면 원문이 “bloated tool sets를 피하라”고 한 조언의 무게가 조금 다르게 읽힌다. 그건 모호성을 피하라는 인터페이스 설계 권고로도 읽히지만, 한 단계 더 들어가면 이 자원의 비용 모델이 dependency가 아니라 임대료에 가깝다는 사실에 대한 함축으로 읽힌다. 백엔드 세계에서 “일단 추가해두고 안 쓰면 그만” 으로 끝날 수 있는 결정은, tool 세계에서는 안 써도 매달 빠져나가는 결정이 된다.
3. 컨텍스트가 한 세션을 넘어설 때 — 세 전략의 짧은 지도
2.1에서 세 전략이 같은 인터페이스의 세 구현이라 했으니, 이 장은 각 구현이 무엇을 빼내고 어떤 상황에 어울리는가 를 짧게 지나간다. 구체적인 적용은 4장에서 한꺼번에 다룬다.
Compaction 은 과거 메시지를 빼낸다. 컨텍스트 윈도우가 한계에 가까워지면 지금까지의 대화를 모델이 요약하고, 새 윈도우는 그 요약으로 다시 열린다. 원본 메시지는 버려진다. Claude Code가 이 방식으로 아키텍처 결정·미해결 버그 같은 것만 요약에 싣고 반복된 tool 호출 결과는 떨어내는 식으로 구현되어 있다고 원문은 예로 든다. 까다로운 건 압축의 강도다. 너무 소극적이면 새 윈도우가 금방 차고, 너무 공격적이면 나중에야 중요해지는 맥락이 사라진다. 대화 흐름이 길게 이어지되 분기가 크지 않은 작업에 어울린다.
Structured note-taking 은 진행 상태를 빼낸다. 에이전트가 작업 중간중간 “지금까지 한 일 / 다음에 할 일”을 컨텍스트 밖 파일에 적어두고, 필요한 순간에만 다시 읽어 들인다. NOTES.md나 to-do list가 원문의 예다. 이름 앞의 structured는 강조어가 아니라 조건에 가깝다. 노트에 구조가 없으면 에이전트가 “끝난 항목”과 “다음에 이어 할 일”을 구분하는 일 자체에 어텐션 예산을 한 번 더 쓰게 된다. 마일스톤이 또렷한 반복 작업에 어울린다.
Sub-agent 는 탐색 과정을 빼낸다. 깊은 탐색이 필요한 일을 메인 컨텍스트가 아니라 별도의 깨끗한 윈도우에서 돌리고, 긴 탐색 과정은 버려진 채 1~2천 토큰짜리 결론만 메인으로 돌아온다. 메인 에이전트는 sub-agent의 중간 trial-and-error, 실패한 검색, 되돌린 추론을 하나도 보지 않는다. 탐색의 분량이 충분히 크고 결론만으로 메인이 다음 결정을 내릴 수 있는 복잡한 연구·분석에 어울린다.
4. 내 작업에 어떻게 적용할 것인가
Spring Boot 회원가입 API 작업은 한 세션에 끝나지 않는다. 요구사항을 쪼개고, 엔드포인트를 설계하고, 구현하고, 테스트를 붙이고, 엣지 케이스를 훑는 일이 여러 세션에 걸쳐 이어진다. 이번에는 이전 글과 달리 세션 안의 문제에 집중해보려 한다. 설계와 구현이 갈라지는 국면에서는 어떤 어휘가 구현 세션에 들어오면 안 되는가로, 구현이 진행되는 국면에서는 어떤 진행 상태를 어떤 모양으로 바깥에 둘 것인가로, 도구가 쌓이는 국면에서는 어떤 도구를 매 턴 시야에 둘 것인가로. 이 장에서는 그 네 국면을 하나씩 짚는다.
4.1. 설계 국면 — 경계를 먼저 그어둔 자리
Spring Boot 회원가입 API를 설계 국면에서 열어보면, 처음 짚게 되는 것은 코드의 구조나 엔드포인트 모양이 아니라 구현 세션에 어떤 어휘가 들어오면 안 되는가에 가깝다. 요구사항을 feature로 쪼개고 테스트 전략을 정하는 초기 단계가 이어지는 동안, 에이전트의 컨텍스트에는 “이 feature 경계를 다시 그어야 하지 않나”, “이 구조가 맞나” 같은 설계 어휘가 자연스럽게 쌓인다.
문제는 이 어휘가 구현이 시작된 뒤에도 시스템 프롬프트에 남아 있으면, 구현 에이전트가 매 턴 이 표현들을 시야 한구석에 둔 채 다음 한 수를 정하게 된다는 점이다. 그러다 특정 턴에서 이 어휘에 이끌려 “잠깐, 이 feature를 다시 쪼개야 하는 거 아니야?” 쪽으로 돌아설 여지가 생긴다. 이 여지를 원칙 몇 줄(“재설계는 하지 마라”)로 막으려 할 수도 있지만, 설계 어휘 자체가 구현 세션의 컨텍스트에 애초에 들어오지 않게 할 수도 있다. 두 국면을 같은 세션 안에 순서만 달리해 처리하는 것이 아니라, 두 국면을 각기 다른 세션으로 분리하고, 각 세션이 보는 프롬프트도 다르게 둔다. 필자가 이 작업에 두 프롬프트를 어떻게 분리했는지 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
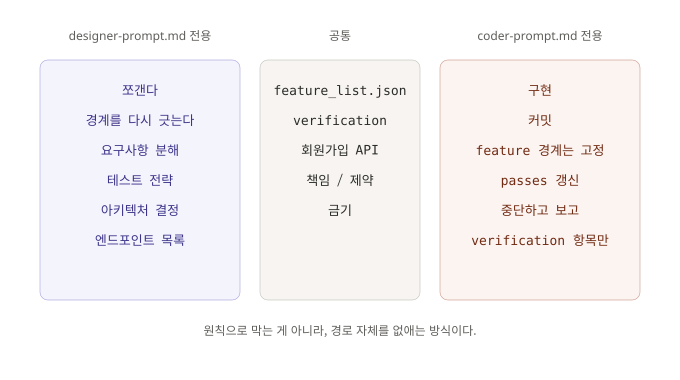
# designer-prompt.md (설계 세션용, 프로젝트 시작 시 한 번만 돈다)
너는 Spring Boot 회원가입 API의 설계를 담당한다.
## 책임
- 요구사항을 feature 단위로 쪼갠다.
- 각 feature의 경계가 애매하면 **다시 쪼개는 것을 망설이지 않는다.**
- 테스트 전략을 feature별로 명시한다 (단위 / 통합 / 경계 조건).
- 각 feature에 verification 체크리스트를 붙인다 (어떤 조건이 만족되어야 완료인가).
## 산출물
- feature_list.json (스키마 v1, passes 필드는 전부 false로 시작)
- 설계 노트 (아키텍처 결정, 엔드포인트 목록, 의존성 판정)
## 금기
- 구현 코드를 쓰지 않는다.
- 테스트 코드를 쓰지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# coder-prompt.md (구현 세션용, 한 feature마다 한 번씩 돈다)
너는 Spring Boot 회원가입 API의 구현을 담당한다.
## 책임
- feature_list.json의 미통과 항목 중 가장 위의 것 하나를 집는다.
- 그 feature의 verification이 전부 통과하도록 코드와 테스트를 쓴다.
- 커밋 단위는 feature 단위. 커밋 메시지에 feature id를 붙인다.
- 작업 종료 시 feature_list.json의 passes를 갱신한다.
## 제약
- **feature 경계는 고정되어 있다. 재설계가 필요해 보이면 중단하고 보고한다.**
- verification 항목에 없는 기능은 추가하지 않는다.
- 다른 feature의 코드는 이번 커밋에서 건드리지 않는다.
## 금기
- 요구사항을 다시 쪼개지 않는다.
- 설계 노트를 수정하지 않는다.
눈에 띄는 차이가 보인다. designer 쪽 책임 항목에는 “다시 쪼개는 것을 망설이지 않는다”가 있고, coder 쪽 제약 항목에는 “feature 경계는 고정되어 있다”가 있다. 그리고 coder 쪽에는 “쪼갠다”, “경계를 다시 긋는다” 같은 설계 동사가 아예 등장하지 않는다. 금기 항목에서 “요구사항을 다시 쪼개지 않는다”로 한 번 호명되고 끝이다. 이 작은 차이가 두 가지 효과를 가져온다.
첫 번째는 권한의 경계다. 에이전트는 매 턴 “내가 할 수 있는 일은 무엇인가”를 시스템 프롬프트에서 재확인하고 움직인다. 그 목록 안에 “feature를 다시 쪼갠다”가 없으면, 에이전트가 설계 작업을 할 경로 자체가 사라진다. 원칙 한 줄로 “재설계하지 마라”를 걸어두는 것과는 다르다. 원칙은 프롬프트 어딘가에 적혀 있고 에이전트는 매번 그 원칙을 참고해서 판단을 내리지만 원칙이 지켜지지 않을 가능성이 있다. 반면 언급조차 하지 않으면 그런 일을 시작할 계기가 없어진다.
두 번째는 토큰의 경계다. 구현 에이전트에게 설계 어휘를 언급해서 시스템 프롬프트에 올라가면 그 후 매 턴 그만큼의 쓰이지 않는 어텐션 예산이 소모된다. 호출되든 안 되든 — 2장에서 임대료 어휘로 짚었듯 — 말이다. 그러니 구현 프롬프트에서 설계 어휘를 빼는 것은, 단순히 “나중에 혼동을 줄이려고” 하는 주석 수준의 정돈이 아니라 어텐션 예산의 고정 지출을 줄이는 조치다. 하나의 조치가 권한의 경계와 토큰의 경계라는 서로 다른 층의 문제를 동시에 해결한다.
다만 이 전략이 모든 작업에 적합하진 않다. 요구사항이 초기에 확정 가능하고 구현 중 근본적인 재설계 가능성이 낮은 작업 — 회원가입 API처럼 도메인이 좁고 외부 의존성이 또렷한 경우 — 에서는 경계가 생산적으로 작동한다. 반대로 구현 중에 “이건 설계 쪽으로 되돌려야 한다”는 판단이 잦은 작업에서는 경계 자체가 비용이 된다. 경계가 잘못 그어진 채로 구현 세션 다섯 개가 지나간 뒤에야 재설계 필요성이 드러나면, 되돌리는 비용이 구현 세션 한두 개를 버리는 것 이상이 된다.
4.2. 구현 국면 — 진행 상태를 어떤 모양으로 바깥에 둘 것인가
경계 안쪽으로 들어오면, 한 세션의 구현 에이전트가 매 턴 붙잡고 있어야 하는 것은 지금 짜는 코드 주변의 좁은 맥락뿐이다. 어느 feature까지 끝났는가, 이번 세션에 무엇을 건드렸는가, 다음 세션이 어디서 이어야 하는가 같은 진행 상태는 컨텍스트 안에 있을 필요가 없다 — 3장의 note-taking이다.
구현 국면에서 이 전략은 한 가지 결정을 더 요구한다. 바깥에 둘 진행 상태를 얼마나 또렷한 모양으로 둘 것인가. 스키마를 강하게 걸면 한 항목 갱신 비용은 싸지지만 왜 를 담을 자리가 없다. 스키마 없는 자연어 노트는 의사결정 궤적을 담을 수 있지만 한 항목 갱신이 문단 전체를 건드리는 편집이 되기 쉽다. 필자는 이 두 끝단을 한 프로젝트에서 동시에 운영해왔다 — 판정 쪽은 feature_list.json, 궤적 쪽은 claude-progress.txt.
1
2
3
4
5
6
7
8
9
10
11
// feature_list.json — 한 feature의 entry
{
"id": "feat-03-email-verification",
"title": "이메일 인증 토큰 발급 및 검증",
"passes": false,
"verification": [
"POST /auth/verify-email 에 유효 토큰 전송 시 200",
"만료된 토큰 전송 시 410 Gone",
"이미 사용된 토큰 전송 시 409 Conflict"
]
}
1
2
3
4
5
6
7
8
9
10
11
# claude-progress.txt — 같은 작업 중의 한 단락
## 2025-10-14 세션 끝
feat-03(이메일 인증) 작업 중. verification 3개 중 2개 통과. 세 번째
("이미 사용된 토큰 → 409")에서 막힘. 원래는 토큰 테이블에 used_at
컬럼 하나 추가하고 not null 체크로 끝낼 생각이었는데, 동시에 두 번
검증 요청이 들어오면 첫 번째가 used_at을 세우기 전에 두 번째가 통과
해버리는 경로가 있음. 낙관적 락(@Version)으로 가는 게 맞아 보이는데,
이건 feat-03의 verification에 없는 결정이라 다음 세션 시작할 때
판단 필요 — 경계 안쪽에서 처리하면 되는가, 설계로 돌려야 하는가.
두 파일이 같은 feat-03을 다루지만 담는 것이 다르다. JSON 쪽은 verification 세 항목 중 어느 것이 통과했는지를 boolean 한 번으로 읽게 해준다. 한 항목의 passes를 뒤집는 편집은 글자 다섯 개를 바꾸는 일이고, 나머지 항목과 파일 구조에는 손댈 이유가 없다. 반면 자연어 노트는 읽기·쓰기 모두 이렇게 압축되지 않는다. 막힌 이유, 올라온 대안, 그 대안이 어디까지 설계를 건드리는지를 한 단락으로 풀어내려면 문장들이 서로 호흡을 맞춰야 한다 — 단락의 뜻이 남는 파일이기 때문이다. 이걸 알고 나면 두 파일은 스키마 여부가 아닌 담는 종류의 정보 자체가 다르다고 보인다. JSON은 판정을 담고, 노트는 판정에 이르는 길을 담는다.

이 구분이 각 파일에 어울리는 작업의 결을 가른다. feature 단위의 완료 여부, 다음 세션이 집어들어야 할 항목 같은 이산적 진행 상태는 JSON 쪽이 싸고 안전하다. “여기서 왜 막혔고, 두 갈래 중 어느 쪽으로 가야 하는지”처럼 이유를 포함하는 진행 상태는 JSON에 우겨넣으면 필드 하나가 긴 문자열이 되어 스키마의 장점이 무너진다. 두 파일을 나눠 쓰는 의미는 각자가 자기에게 맞는 정보만 담을 때에만 살아남는다 — feature_list.json에 자연어 메모가 자라나거나 claude-progress.txt에 판정 성격의 문장이 중복 기록되면 곧 두 파일 사이에 어느 쪽이 진실인지 판정하는 비용이 매 세션 깔린다.
그리고 이 전략만으로는 부족한 작업도 있다. 하나의 결정을 내리기 위해 여러 갈래의 탐색을 병렬로 파 내려가야 하는 순간에서는 파일 바깥에 둔 진행 상태보다 탐색의 과정 자체를 어디서 돌리느냐가 더 중요한 문제가 된다.
4.3. 구현 국면 — 탐색 자체를 어디서 돌릴 것인가
로그인 직후 간헐적으로 401이 뜬다고 하자. 의심 원인은 세 가지다 — 세션 만료 경계값, 토큰 검증 로직의 경계 조건, Redis 세션 캐시의 교체 정책. 각 갈래마다 재현 시나리오를 짜고 로그를 뒤지고 설정값을 확인하는 데 토큰이 수천에서 수만씩 쓰이는데, 이 세 갈래를 한 세션의 컨텍스트 안에서 모두 굴리면 어느 갈래가 어디까지 갔는지, 어떤 가설이 기각되었는지가 하나의 윈도우 안에서 뒤섞이기 시작한다. 이럴 땐 sub-agent 전략이 필요하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 개념 의사코드 — 실제로 돌려본 구성이 아니라 "이런 모양으로 돌린다"는 스케치
# 워커는 새 컨텍스트를 열어 자기한테 주어진 갈래 하나만 파고든다.
# 탐색 중에 쌓이는 토큰은 워커 안에 머물고, 메인 세션에는 결론 요약만 넘어간다.
worker = SubAgentWorker(
task = "로그인 직후 401 간헐 발생 — 세션 만료 경계값 의심",
context = "clean", # 메인 세션 히스토리 상속 없음
scope_files = ["SessionConfig", "AuthFilter", "logs/2025-10-12"],
)
result = worker.invoke()
# result = {
# conclusion: "세션 만료는 이 문제의 원인이 아님",
# evidence: ["재현 시나리오 2건 모두 만료 전에 401 발생", ...],
# }
# 메인 세션이 받는 건 result 하나다.
# 재현 시나리오 전문, 뒤져본 로그, 기각한 가설은 메인 컨텍스트에 들어오지 않는다.
포인트는 중간 과정을 메인에 들이지 않는다는 데에 있다. 만약 메인 세션이 세 갈래의 탐색 과정을 모두 본다면, 어느 결론이 어느 갈래에서 나왔는지를 되짚는 일에 어텐션 예산이 낭비된다.
4.4. 운영 국면 — 매 턴 시야에 둘 도구를 어떻게 고를 것인가
회원가입 API 작업을 여러 세션에 걸쳐 돌리는 동안, 필자의 프로젝트 루트 .mcp.json에 등록되어 있던 MCP 서버 목록은 한때 이런 모양이었다.
각 서버의
command·args·env는 이 글의 관심사가 아니라 주석으로 축약했다 — 실제 파일은 주석 없는 순수 JSON이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// .mcp.json (전) — 붙여두면 편해 보여서 붙여둔 상태
{
"mcpServers": {
"filesystem": { /* 로컬 파일 읽기/쓰기 */ },
"git": { /* 커밋/diff/로그 */ },
"github": { /* 이슈, PR */ },
"mysql": { /* DB 스키마, 쿼리 */ },
"redis": { /* 키 조회 */ },
"fetch": { /* 임의 URL 본문 가져오기 */ },
"web-search": { /* 일반 웹 검색 */ },
"puppeteer": { /* 브라우저 자동화 */ },
"postman": { /* 저장된 요청 실행 */ }
}
}
이 목록이 다음처럼 줄었다.
1
2
3
4
5
6
7
8
9
// .mcp.json (후) — 판정을 통과한 줄만 남긴 상태
{
"mcpServers": {
"filesystem": { /* 로컬 파일 읽기/쓰기 */ },
"git": { /* 커밋/diff/로그 */ },
"mysql": { /* DB 스키마, 쿼리 */ },
"redis": { /* 키 조회 */ }
}
}
여기서 볼 것은 어떤 줄이 남고 어떤 줄이 빠졌는가 다. 빠진 다섯 줄은 쓸모없는 도구여서 뺀 게 아니다. 에이전트가 매 턴 도구 목록을 읽는 비용이 호출 여부가 아니라 등록된 줄 수에 비례한다는 것을 알고 나니, 판정 기준이 바뀌었다. “이 도구가 안 쓰이는가” 가 아니라 “이 도구가 매 턴 이 자리를 차지할 만큼 자주 필요한가” 다.
github이 먼저 빠졌다. Git 이력을 확인하는 일의 99%는 git 하나로 해결되고, 이슈와 PR은 브라우저로 여는 편이 더 빠르다. 같은 공간을 다루는 도구 두 개가 붙어 있으면 에이전트 입장에서는 매 턴 “어느 쪽을 써야 하는가”를 한 번 더 판정해야 한다. fetch와 web-search도 비슷한 이유로 제거했다. 회원가입 API 구현에서 외부 URL을 가져오거나 일반 검색을 돌릴 필요는 거의 없었고, 있다 해도 브라우저로 한 번 여는 쪽이 더 의미가 있다. puppeteer는 E2E 재현 시나리오가 필요한 세션에서만 사용했다. postman은 로컬 curl 한 줄로 대체되는 경우가 대부분이어서 제거했다.
이 판정은 프로젝트마다 달라질 수 있다. “매 턴 이 자리를 차지할 만큼 자주 필요한가”로 초점을 맞추면 상황에 맞는 조합이 나온다. 그리고 이 초점은 도구에만 해당하지 않는다. 시스템 프롬프트의 어느 줄, 예시의 어느 덩어리, 설명 문서의 어떤 내용에도 같은 초점을 대볼 수 있다.
5. Reference
이 글의 출발점이 된 원문은 Anthropic Engineering 블로그의 Effective context engineering for AI agents다. 앞서 다룬 Effective harnesses for long-running agents가 세션 경계 너머에 무엇을 남길지를 다뤘다면, 이 글은 한 세션 안의 컨텍스트 윈도우에 무엇을 들이고 무엇을 빼낼지를 다룬다. 시리즈의 이전 글을 함께 두고 읽으면 두 글의 관심사가 바로 위아래로 맞물리는 결이 보인다. 1장에서 짚은 context rot — 컨텍스트가 길어질수록 모델의 회상 정확도가 조용히 깎인다는 현상 — 의 실증적 근거는 Chroma의 기술 보고서 Context Rot: How Increasing Input Tokens Impacts LLM Performance (Hong, Troynikov, Huber, 2025)에 정리되어 있다. Chroma 보고서는 원문이 전제로만 가져다 쓴 이 현상을 18개 모델에 걸쳐 실제로 측정한다. “긴 컨텍스트 윈도우가 있다는 것”과 “그 윈도우를 균일하게 쓴다는 것”이 서로 다른 문제임을 눈으로 확인하고 싶을 때 이 자료를 찾아보면 된다.
닫는 말
판정이 이 글의 뼈대였다. 어느 feature가 통과했는지, 어느 도구가 등록될 만큼 자주 쓰이는지, 어느 어휘가 구현 세션에 들어와도 되는지. 그런데 이 판정들은 전부 단독으로 내려졌다 — 사람이 에이전트에게 거는 기준이거나, 에이전트가 자기 진행을 스스로 채점하는 방식이었다. Anthropic이 이어 올린 글은 이 판정을 두 에이전트에게 맡긴다. 한 에이전트는 일을 하고, 다른 에이전트는 그 일을 채점한다. 무엇을 채점하느냐, 채점자를 어떻게 길들이느냐, 그리고 이 둘을 같이 쓸 가치가 있는 일은 어디까지인가를 다음 글에서 다룬다.