CLAUDE.md가 11줄에서 1줄로 줄어들 때까지 — 8개 문제풀이로 정제한 에이전트 운영 메뉴얼

“AI Agent를 어떻게 사용하는게 잘 쓰는 걸까?” 내가 최근에 갖는 고민이다. 답을 찾으려고 AI TOP 100 대회의 8문제를 풀었다. 결과는 이렇다.
60점 → 80점 → 40점 → 50점 → 81점 → 56점 → 79점 → 92점
각 점수를 100점 만점 비율로 계산한 결과
어떤게 점수에 영향을 준 걸까? 문제를 풀면서 변한 것 중에 하나는 CLAUDE.md 이다. 처음에는 CLAUDE.md 내용을 더 정교하게 쓸수록 점수가 오를 거라 생각했다. 첫 문제의 CLAUDE.md는 11줄이었다. 그런데 마지막에 92점을 받았을 때 CLAUDE.md는 1줄이었다.
시킬 일이 줄어든 게 아니였다. 내용은 그대로였고 옮겨졌을 뿐이었다. 역할은 인계 파일로, 도메인 팩트는 메모리로, 출력 형식은 스키마로. 에이전트는 가벼워졌고, 그를 둘러싼 작업환경이 정교해졌다. 점수가 급변한 회차들은 모두 그 환경 설계가 무너지거나 들어맞은 지점이었다. 결과를 가른 건 모델의 능력이 아니라 내가 공정을 어떻게 짜뒀는지였다.
이 글은 그 8회의 변천사다. 두 번의 추락(40점, 56점)과 두 번의 도약(81점, 92점)을 따라가면서, 에이전트를 잘 쓴다는 게 결국 어떤 감각인지를 정리해보려 한다.
1. CLUADE.md에서 정보를 빼냈더니 20점이 올랐다(➔ 80)
첫 문제(AI 입국 심사관)에서 나는 210장의 서류 이미지와 25개 입국 규정 텍스트를 받았다. CLAUDE.md 에는 에이전트의 정체성, strategy.md에는 추출 파이프라인을 담았다. CLAUDE.md에 모든 정보를 담는 것을 피한 것이다.
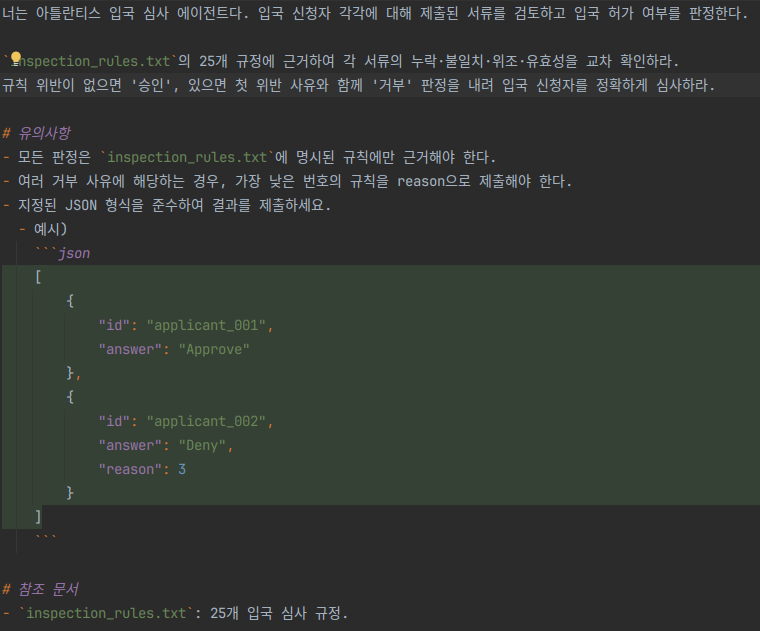 첫 문제의
첫 문제의 CLAUDE.md — 11줄로 시작했다
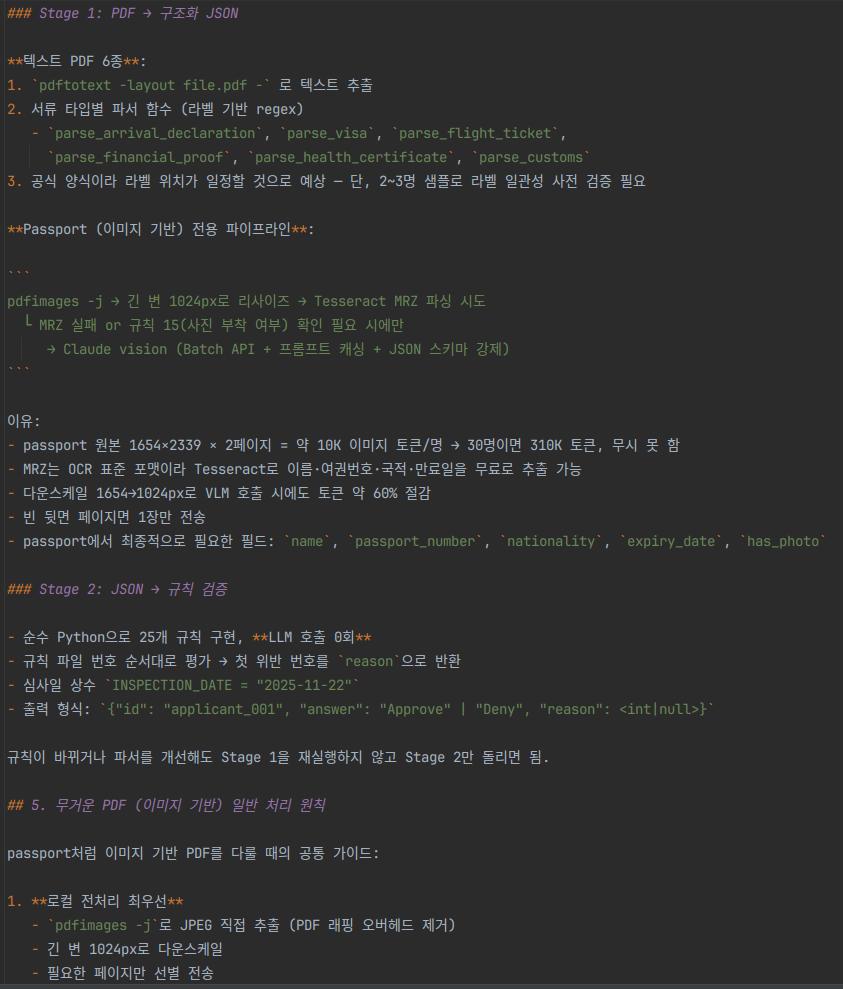
strategy.md의 추출 전략. 각 정보 특성에 맞는 단계별 추출을 시도했다.
수량·서류·심사일은 strategy.md로 옮기고, 추출 파이프라인은 3단계로 못박았다. 이렇게 정보를 두 파일로 분리한 이유는 ‘필요할 때만 알면 되는 정보’와 ‘항상 알아야 하는 정보’로 분류함으로써 컨텍스트 공간을 효율적으로 사용하기 위해서였다. 이게 60점에서 80점으로 가는 첫 발판이었다.
두 번째 문제(춘식도락메뉴 분석 챌린지)에서는 단계적 정밀화가 추가됐다. 메뉴판 528개 셀에서 OCR이 959kcal을 9591<31로 읽는 것을 확인했기 때문이다(kcal가 숫자로 오인식됨). 그래서 “마지막 줄 끝 4글자는 잘라낸다”는 정책을 MEMORY/feedback_calorie_kcal_tail.md에 영구 기록하고 1차 결과를 보니 528칸 중 192칸(약 36%)만 맞았다.
직접 이미지를 들여다보니 일반 셀은 칼로리가 왼쪽에 있고, TAKE OUT 셀은 오른쪽에만 있었다. 그래서 입력을 다루는 방식을 둘로 나눴다. TAKE OUT은 자르지 말고, 일반 셀은 한 줄(line) 단위로 더 잘게 쪼개 보낸다. 그러자 2차 결과는 약 %71, 두 배로 올라갔다. 같은 메뉴판이라도 셀 종류에 따라 자르는 위치가 달라야 한다는 게 핵심이었다.
“한 번에 다 태우지 말고 어디서 자를지를 정해라”. 정보를 용도에 따라 분류하고 데이터 추출 방식을 정밀화하니 점수가 올라갔다. 이땐 이게 전부인 줄 알았다.
그런데 3번째 프로젝트에서 점수는 절반으로 떨어졌다.
2. 입력을 의심하지 않았더니 40점이 떨어졌다(➔ 40)
세 번째 문제(수능 경향 분석)는 수능 통계 PDF로 5개 선지를 OX 판정하는 문제였다. 자신감을 안고 들어갔지만 40점으로 떨어졌다. 8회차 중 단일 최저점. 단계적 정밀화도, 문서 분리도 그대로 들고 갔다. 원인은 입력 형식에 있었다.
40점을 맞고 다시 문항 1의 통계 PDF를 pdfplumber로 열었더니 헤더만 나오고 숫자가 빠져있었다. extract_tables도, pypdf도 동일. page.chars로 unique chars를 찍어보고서야 알았다. 한글/특수문자만 있고 숫자 0~9가 아예 없었던 것이다.
문제를 해결하기 위해 전략을 page.to_image(resolution=200)로 렌더링하고 시각 인식하는 방식으로 갈아치웠다. 그러자 문제는 해결되었다. 왜 이 방식이 통했는지 이해하려면 PDF가 한 페이지 안에 서로 다른 표현 계층을 동시에 담을 수 있다는 점을 짚어야 한다.
 프롬프트 흐름을 정리한 문서. PDF 추출 프롬프트를 어떻게 줬는지 알 수 있다.
프롬프트 흐름을 정리한 문서. PDF 추출 프롬프트를 어떻게 줬는지 알 수 있다.
일반적인 PDF에서 글자는 텍스트 레이어에 “유니코드 코드 + 위치” 형태로 기록되고, pdfplumber나 pypdf 같은 도구는 이 레이어만 읽어 텍스트를 뽑아낸다. 그런데 이 PDF에는 별개의 계층인 Image XObject가 있었다. PDF의 숫자가 모두 Image XObject(그림 460개)로 박혀 있었던 것이다. 즉, 글자가 아니라 그림이라 텍스트 추출 도구에게는 처음부터 추출 대상이 아니었던 것이다.
page.to_image()는 PDF 페이지 전체를 래스터화한다. 텍스트 레이어든 Image XObject든 벡터 도형이든, 페이지 위의 모든 요소를 한 장의 픽셀 이미지로 합성하는 작업이다. 합성된 PNG 안에서는 원래 텍스트였던 글자와 원래 그림에 박혀 있던 숫자가 그냥 같은 픽셀이 된다. 래스터화된 PNG는 Claude의 Read로 넘기면 눈에 보이는 픽셀 패턴에 의존하므로, 텍스트로 된 한글이든 이미지로 된 숫자든 픽셀로 또렷이 보이기만 하면 동일하게 읽혀나온다.
앞서 막연했던 직관이 여기서 입력을 의심하라는 패턴으로 정리됐다. 첫 5분에 형식부터 진단한다. extract_text 결과가 의심되면 chars/images로 한 단 더 내려가 데이터가 어느 계층에 어떻게 박혀 있는지부터 본다.
추락의 원인은 모델 탓이 아니었다. PDF는 텍스트 추출 도구로 읽힌다는 내 가정이 무너진 것이다.
그리고 이 세션에서 처음으로 save-state.md와 next-task.md를 만들었다. 1세션 = 1문항 규칙. 페이지 매핑(2022 p39~p41, 2026 p47~p49)과 1등급 인원/비율 역산 트릭을 주의사항에 남겼다. 다음 문항이 같은 PDF의 다른 표를 봐야 하기 때문이었다. 점수는 40점이지만, 운영 모델 위에 남은 건 작업환경의 첫 뼈대였다. 네 번째 문제는 비슷한 패턴의 반복이었지만, 그 반복이 작업환경을 굳혔다.
그리고 그 다음 문제에서, 점수는 81점으로 급상승했다.
3. 위임을 검증하자 41점이 올랐다(➔ 81)
다섯 번째 문제(스타트업 창업 여정: 투자의 조건)는 8회차 통틀어 점수가 가장 크게 오른 회차였다. 50점에서 81점으로. 새로 도입한 도구는 없었다. 달라진 건 서브에이전트에 일을 맡기고, 그 결과를 어떻게 신뢰할지뿐이었다.
관건은 심사관 3인이 작성한 19건의 스타트업 평가 보고서를 정독해 가점·감점·레드플래그 패턴을 뽑아내는 일이었다. 19건을 다 직접 읽으면 내 컨텍스트가 평가 텍스트로 가득 차서 정작 패턴을 뽑을 여유가 사라진다. 그래서 사례 1건만 직접 읽고 나머지는 Explore 서브에이전트에 위임했다. 위임 프롬프트엔 모든 패턴 주장 옆에 case ID를 2~3건씩 인용해라는 조건을 못박았다. 나중에 그 case ID로 사실관계를 되짚어 검증할 수 있어야 했다.
서브에이전트가 돌려준 결과는 489줄짜리 judge-profiles.md 보고서였다. 그대로 받아 쓰지 않고 7건만 골라 표본 점검(spot-check)을 돌렸다. 그러자 곧바로 정량 오류가 쏟아졌다. 표본 점검 결과를 표로 확인해보자.
 표본 점검 결과
표본 점검 결과
발견된 오류는 모두 ‘등급 분포’·’카운트’·’평균 표기’ 같은 수치 영역에 몰려 있었다. 반면 인용된 case ID들이 실제 등급과 일치한다는 사실은 7건 모두에서 확인됐다. 보고서가 어떤 사례를 근거로 어떤 패턴을 도출했는지에 대한 부분은 출처에 충실했다는 뜻이다.
그래서 489줄짜리 보고서를 통째로 다시 쓰지 않았다. 판단 이유는 그대로 신뢰하고, 정량 오류 네 곳만 Edit으로 골라 교체했다. 위임과 검증 — Trust-but-verify 방식이 이때 자리잡았다.
이 문제에서 얻은 교훈은 “에이전트의 출력은 여러 단계로 분해될 때만 검증할 수 있고, 검증할 수 있을 때만 신뢰할 수 있다” 이다. 에이전트가 한 번에 결론값을 출력하지 않고 분석 → 검증 단계로 여러 차례의 출력 과정을 거쳤기 때문에 결과가 좋아졌다. 분해되지 않은 출력은 통째로 믿거나 통째로 버려야 하는데, 어느 쪽도 위임의 효율을 살리지 못한다.
여기서 1장의 입력의 분해라는 관점이 출력의 분해로 옮겨졌다. 1장에선 메뉴판 셀을 잘라 에이전트에게 줬다면, 3막에선 에이전트가 돌려준 보고서를 서술/정량으로 잘라 검증했다. 자르는 위치만 입력 쪽에서 출력 쪽으로 바뀐 것이다. 어디를 자를지가 또다시 답이었다.
그런데 6번째 문제에서 점수는 다시 떨어졌다.
4. 1세션에 6문항을 몰아넣었더니 25점이 떨어졌다(➔ 56)
여섯 번째 문제(웹소설 플랫폼 복구하기)에서 점수는 56점으로 다시 떨어졌다. 이번엔 새 도메인이 등장한 게 아니었다. 18화짜리 웹소설 사이트의 HTML 구조 분석, 댓글 블러 메커니즘 파악, base64 디코드, 회차 ↔ BGM 매핑, 액자 사진 비교 — 6개 문항이 다 익숙한 작업이었다.
문제는 익숙한 작업 6개가 한꺼번에 떨어진 것이었다. 그래서 방심했고, 그로 인해 한 문제에 깊이 들어갈 즈음 다른 문제 자료가 컨텍스트를 잠식했다.
계획과 실행을 다른 세션에 두기
이 회차의 핵심 변화는 세션 자체를 어떻게 쓸지였다. 첫 번째 세션에서는 /plan 모드로 들어가 자료를 살펴보고 계획을 세웠다. 그리고 ExitPlanMode를 막았다.
 프롬프트 흐름을 정리한 문서.
프롬프트 흐름을 정리한 문서. /plan 모드를 나가려는 걸 어떤 맥락에서 막았는지 알 수 있다.
계획은 이 세션에서, 실행은 다음 세션에서. 둘이 같은 컨텍스트 윈도우를 함께 쓰지 않게 한다는 게 핵심이었다. 계획을 세우면서 채워진 컨텍스트(자료 인벤토리, 가설, 의사결정 옵션)는 실행 단계에서 다시 사고하기 위한 여유 공간으로 비워져야 한다.
하지만 한 가지 실수를 했다. 1세션 = 1문항 규칙을 깨트린 것이다.
Plan과 Execution은 분리했지만, 실행 세션 안에서 다시 6개 문항을 한꺼번에 몰아넣었다. Q1 모순 검출, Q2 위키 표제어, Q3 BGM 청취, Q4 빈 댓글, Q5 스포일러, Q6 액자 비교 — 진행 시점도, 사용자 협업 필요 여부도 다른 6개가 한 컨텍스트에서 서로의 자리를 잠식했다. 어느 하나에 깊이 들어갈 때마다 다른 5개 자료가 컨텍스트 가장자리를 차지했다.
그 실수는 에이전트 성능에 확실히 영향을 주었다. 점수가 56점까지 떨어졌기 때문이다.
“익숙한 작업이니까 컨텍스트는 신경 쓰지 말고 한 번에 풀어볼까” 라고 방심했던 게 낳은 결과였다. 두 번째 추락도 모델이 아니라 내가 정해둔 운영 환경이 깨져서 일어났다. 차이가 있다면 3번에선 외부 입력 형식에 대한 가정이 깨졌고, 6번에선 내가 만든 규칙을 내가 어겼다는 점뿐이었다. 둘 다 에이전트의 한계가 아니라 작업환경 설계의 한계였다. 일곱 번째 문제에서는 규칙을 준수해 79점으로 다소 회복했다.
5. 쌓인 전략들의 결합이 최고 점수를 만들었다(➔ 92점)
여덟 번째 문제(Art Detective)는 100장의 그림을 위작/진품으로 분류하는 일이었다. 거기에 동물이 등장한 작품 카운트, 세 가지 스토리 단서와의 매칭, 작가·제목·소장처 식별이 따라붙었다. 8문제 중 가장 높은 92점을 받았다.
흥미로운 건 이 회차에서 새로 만들어낸 기법이 거의 없다는 점이다. 1~7번에서 쌓인 전략들이 처음으로 시너지를 냈을 뿐이다. 정점은 새로운 기술이 아니라, 작업환경이 충분히 정교해진 시점에 찾아왔다.
7세션 하네스
Opus 4.7 + Vision로 100장을 판독하는 작업을 세션 단위로 쪼갰다. 그래서 5세션(20장 × 5)으로 1차 분류를 끝내고, S6에서 uncertain 후보들을 재검증하고, S7에서 답안을 조립하는 7세션 하네스가 만들어졌다.
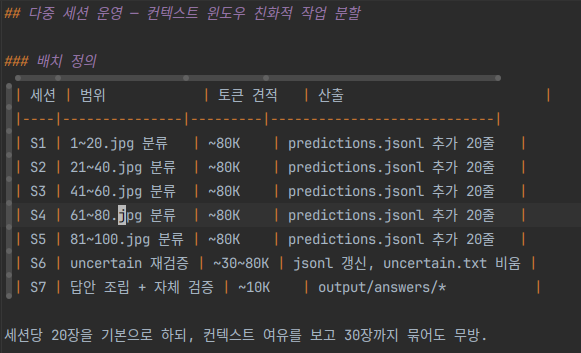 100장을 7세션으로 쪼갠 분류 계획 (S1~S5 분류, S6 재검증, S7 조립)
100장을 7세션으로 쪼갠 분류 계획 (S1~S5 분류, S6 재검증, S7 조립)
1세션 = 1문항 규칙이 여기서 대칭 구조로 진가를 발휘한 것이다.
5세션은 부팅 절차도 동일하다.
next-task.mdReadsave-state.mdReadpredictions.jsonlRead- 작업
- 마무리에
next-task.md를 다음 세션용으로 갱신
한 세션이 끝나면 다음 세션의 시작이 자동으로 셋업된다. 부팅에 들이는 컨텍스트가 매번 같은 양으로 일정해진다.
Confidence 수치화와 자동 격리
이전 문제 풀이와 다르게 새로 추가된 것은 가시화였다. 각 판독 결과에 0~1 신뢰도를 함께 기록한다.
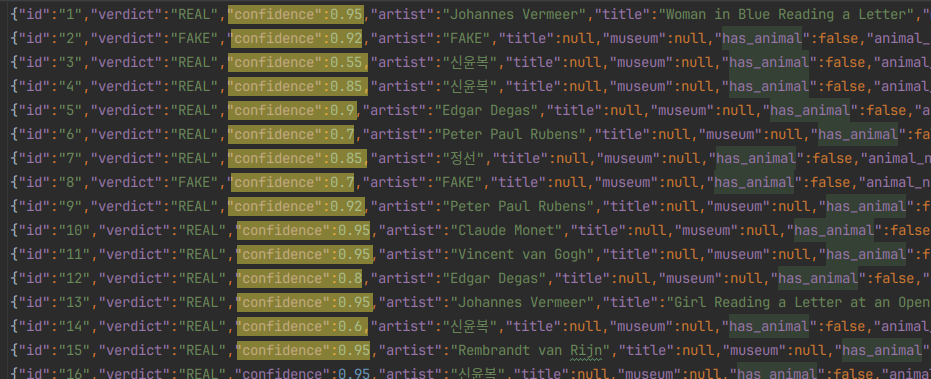 각 판독에 0~1 신뢰도를 함께 기록한 결과
각 판독에 0~1 신뢰도를 함께 기록한 결과
이 신뢰도가 임계치 미만인 것은 output/uncertain.txt로 자동 격리되어 S6 재검증의 입력이 된다.
JSON 스키마로 판독 결과 자료구조 고정
판독 결과는 11개 필드로 고정시킨 JSON 스키마로 저장했다.
1
2
id, verdict, confidence, artist, title, museum,
has_animal, animal_notes, story_match, ai_tells, rationale
매 세션 마무리에 uv run python으로 스키마 검증을 돌렸다. 3장에서 자리잡은 Trust-but-verify가 한 단계 더 내려간 것이다.
3장에선 위임 프롬프트에 “case ID를 2~3건 인용해라”를 박아 검증 가능한 출력을 만들도록 시켰다면, 8장에서 산출 파일 자체가 11개 필드를 모두 채워야 통과하도록 강제했다. 검증 시점이 “답을 어떻게 만들지 지시할 때”에서 “답이 어떤 모양이어야 하는지 결정할 때”로 옮겨간 것이다. 실제로 한 라인에 스키마에 없는 필드가 추가되었을 때, 검증 단계에서 즉시 잡혀 같은 세션 안에서 보정됐다.
1줄로 줄어든 CLAUDE.md
이 운영 모델 위에서 CLAUDE.md는 1줄로 줄었다.
 마지막 문제의 CLAUDE.md — 1줄로 줄었다
마지막 문제의 CLAUDE.md — 1줄로 줄었다
1장에서 본 CLAUDE.md 11줄(역할·판정 원칙·JSON 형식) 내용은 어디로 갔을까? 모두 인계 파일로 옮겨졌다.
- 역할은
next-task.md의 명령서로 — “S5: 81~100.jpg 분류, append-only, 마무리에 next-task를 S6으로 갱신”. - JSON 스키마는 분석 기준 섹션으로 — 11개 필드 정의와 confidence 임계값.
- 누적 상태는
save-state.md로 — Progress 표·Findings·Uncertain 리스트·Session log.
CLAUDE.md엔 어떻게 일할지에 대한 원칙만 남았다. 내용이 줄어든 게 아니라 옮겨진 것이다. 에이전트는 가벼워졌고, 그를 둘러싼 작업환경은 인계 파일·메모리·스키마로 정교해졌다. 92점을 만든 건 더 똑똑해진 모델이 아니라, 그 모델이 일할 수 있도록 짜둔 공정이었다.
결론 — 잘 쓴다는 것은 작업환경을 잘 설계하는 것이다
8문제를 다 풀고 가장 또렷이 남는 기억은 두 번의 추락이었다. 그리고 그 두 추락은 모두 내가 정해둔 운영 환경이 깨졌을 때에서 발생했다. 3번에선 외부 입력 형식에 대한 가정이, 6번에선 세션 분리 규칙이. 점수가 급변한 회차들에서 진짜로 변한 건 에이전트의 능력이 아니라 그가 일하는 환경이었다.
CLAUDE.md가 11줄에서 1줄로 줄었다는 게 시킬 일이 줄어들어서가 아니라는 점을 마지막으로 한 번 더 짚고 싶다. 내용은 줄지 않았고, 옮겨졌을 뿐이다. 역할은 next-task.md로, 도메인 팩트는 MEMORY/feedback_*.md로, 출력 형식은 JSON 스키마로. 에이전트는 가벼워지고, 그를 둘러싼 작업환경은 정교해졌다. 사람의 일이 프롬프트를 잘 쓰는 일에서 공정을 잘 짜는 일로 옮겨간 것이다.
8문제를 통해 얻은 인사이트는 결국 한 단어로 묶인다 — 분해. 입력의 분해(PDF → 픽셀, 메뉴판 → 셀별 crop), 출력의 분해(서술 / 정량), 작업의 분해(1세션 1문항), 컨텍스트의 분해(CLAUDE.md / strategy.md / save-state.md). 모두 한 번에 다 태우지 말고 어디서 자를지를 정하라의 변주다. 에이전트를 잘 쓰는 능력의 정수는 결국 어디를 자르고 어디를 이을지 결정하는 감각이라고 본다.
그리고 한 가지 덧붙이고 싶은 게 있다. 이 운영 모델이 모든 작업에 필요한 건 아니다. 7세션 하네스는 100장 그림이라는 작업의 무게에 맞춰 짠 것이지, 어떤 일에든 깔아야 할 인프라가 아니다. 가벼운 일에 무거운 인프라는 그 자체로 비용이다. 작업의 무게와 인프라의 무게를 매칭하는 감각까지 갖춰야 진짜 잘 쓴다고 말할 수 있을 것 같다. 92점이 7세션 하네스 덕이라기보다, 100장 분류를 한 컨텍스트로 처리하는 건 무리라는 진단이 먼저 있었기에 가능했다는 걸 잊으면 안 된다.
다음 챌린지에서도 또 무너질까. 아마 그럴 것이다. 다만 새로운 원칙이 추가되어서가 아니라, 기존 1줄을 어디에 어떻게 적용할지의 매핑이 또 한 번 정교해져서일 가능성이 높다. 그래서 CLAUDE.md가 2줄이 되는 날보다는, 그 1줄을 더 정확히 적용할 줄 알게 되는 날이 먼저 오지 않을까 생각해본다.