AI 에이전트는 자기 일을 채점하지 못한다 — Anthropic이 제시한 Generator·Evaluator 하네스 설계

이전 두 글에서는 AI 에이전트의 병목 두 가지를 짚었습니다. 1편은 작업 머리가 가득 차면서 앞 내용을 잃어버리는 문제, 2편은 기억 공간이 비어 있는데도 성능이 무너지는 문제였습니다. 처방은 각각 하네스와 컨텍스트 엔지니어링이었습니다.
그런데 두 처방을 모두 깔아둬도 더 복잡한 작업에서는 에이전트가 슬쩍 궤도를 벗어났습니다. 결과물은 그럴듯해 보이는데, 막상 열어보면 핵심 동작이 비어 있는 식이었죠. 더 이상한 건 그 비어 있는 결과물을 에이전트 본인은 “잘 끝냈다” 고 자랑스럽게 보고한다는 점이었습니다. 이 패턴을 분해해보니, 같은 결의 실패가 두 가지 모양으로 반복되고 있었습니다.
TL;DR
AI 에이전트 한 명에게 일을 맡기면 대충 마무리해버립니다. 반면 하네스를 매어주면 독창적인 결과물을 만들 때까지 계속해서 시도하고, 꼼꼼하게 마무리합니다.
1. 다른 의미의 하네스(harness)
실패 패턴을 보기 전에 단어부터 정리하겠습니다. 1편에서는 하네스를 병목을 해소하는 틀 정도로 좁게 썼지만, 단어 자체는 더 넓은 의미를 갖습니다.
하네스의 본래 뜻은 말에게 채우는 마구입니다. 말 한 마리가 마부의 의도대로 정확히 가게끔 잡아주는 장치죠. AI 에이전트의 하네스도 결을 그대로 이어받습니다. 모델이 우리가 원하는 방향으로 움직이도록 잡아주는 제어 설계 전체를 가리킵니다. 1편에서 다룬 세션 간 인계 파일도, 2편의 Sub-agent 기법도, Tool 배제도 여기에 포함됩니다.
2. 왜 복잡한 문제에서 실패했는가?
2.1 패턴 1: 지치면 얼렁뚱땅 끝낸다
 두뇌가 가득차면서 얼른 끝내고 싶어하는 AI의 모습
두뇌가 가득차면서 얼른 끝내고 싶어하는 AI의 모습
학원에서 학생에게 5시간 연강 후 100문제를 풀게 한다고 해보죠. 각 강의는 전 강의 내용을 다시 되짚지도 않습니다. 학생은 아마 2시간까지는 어떻게든 수업 내용을 머리 속에 담아보려고 하겠지만 3시간이 되가면 곧 앞에서 배운 내용도 기억나지 않고, 듣다가 지쳐서 문제를 대충 풀어버릴 거에요.
AI Agent도 똑같습니다. 대화가 길어지면 앞에서 나눈 내용이 흐릿해지고, 중요한 과제가 남아 있는데도 대충 끝내버립니다. Anthropic은 이 행동을 컨텍스트 불안(context anxiety) 이라 부릅니다.
2.2 패턴 2: 자신의 OMR 카드를 스스로 채점하면 “다 맞았어!” 라고 한다
 스스로를 좋게 평가하려는 AI의 모습
스스로를 좋게 평가하려는 AI의 모습
학원에서 푼 100문제를 스스로 채점하라고 한다면, 학생은 틀린 문제도 선생님 눈치를 보며 동그라미를 그릴 것입니다.
AI Agent도 똑같습니다. 웹사이트를 만들게 했을 때 분명 클릭이 안 되는 버튼이 있는데도 “기능이 깔끔하게 구현됐습니다” 라고 자신 있게 평가합니다. 검증 가능한 코드 영역에서도 이 현상이 종종 나타나고, 디자인같은 주관적 영역에서는 더 심해집니다.
3. 어떻게 해결할 수 있는가?
3.1 바톤 터치
 다음 사람에게 인계해서 최상의 상태를 유지하는 전략
다음 사람에게 인계해서 최상의 상태를 유지하는 전략
컨텍스트 불안은 1편에서 풀어둔 방식이 그대로 통합니다. 학생 한 명이 끝까지 끌고 가지 않고, 일정 지점에서 친구에게 바톤 터치하고 손을 떼는 것으로요.
앞 학생은 문제를 푸는데 필요한 핵심 내용을 뒷 학생에게 설명하고, 마지막 학생이 100문제를 풉니다. 따라서 각 학생(= AI)은 지치지 않게 되고, 대충 끝내지 않게 됩니다.
바톤 터치를 하지 않고 명상 시간(= AI의 컴팩션)을 줘서 머리 속을 정리하는 방법도 있지만, 명상 후에도 뇌의 피로감(➝ 컨텍스트 불안)은 남아있게 됩니다.
3.2 타인 채점
 스스로를 비판적으로 평가하는 것보다 타인이 엄격하게 평가하는게 쉽다
스스로를 비판적으로 평가하는 것보다 타인이 엄격하게 평가하는게 쉽다
자기평가 문제는 다른 학생에게 채점시켜서 해결합니다.
여기서 한 가지 의문이 고개를 듭니다. “채점하는 학생(= AI)도 결국 학생 아닌가? 학생끼리 점수를 후하게 주지 않을까?”
맞습니다. 하지만 Anthropic이 찾아낸 핵심 인사이트는
“자기 답지를 냉정하게 채점시키는 것보다 독립된 채점자를 엄격하게 만드는게 더 쉽다.”
입니다.
4. 디자인 실험: “아름다운가?”를 “기준에 부합하는가?”로 바꾸기
Anthropic의 Prithvi Rajasekaran은 바톤 터치와 타인 채점 방법을 먼저 프론트엔드 디자인에 실험했습니다. 그는 작은 통찰 하나로 시작했습니다.
- “이 디자인이 아름다운가?” 같은 모호한 질문에는 모델도 사람도 일관된 답을 내놓지 못한다. 하지만 “이 디자인이 우리가 합의한 좋은 디자인의 원칙을 따르는가?” 로 질문을 바꾸면, 답이 한곳으로 모이기 시작한다.
이 통찰을 기저에 깔고, Generator(생성자)와 Evaluator(평가자) 양쪽 프롬프트에 동일하게 넣을 채점 기준 네 가지를 작성했습니다.

이렇게 채점 기준이 있으면, 평가자가 어디를 짚고 어디를 통과시킬지 결정할 수 있고, 가중치를 다르게 줄 수도 있습니다. Rajasekaran은 1·2번에 가중치를 더 실었습니다. 그 이유는 Claude가 3·4번은 이미 잘하지만, 1·2번은 잘 하지 못하는 약점이 있어서, 그 약점을 누르고 그 부분에 집중해서 모험하게 만들고 싶었기 때문입니다.
4.1 Generator와 Evaluator의 협업
둘의 협업 방식은 이렇게 굴러갑니다.
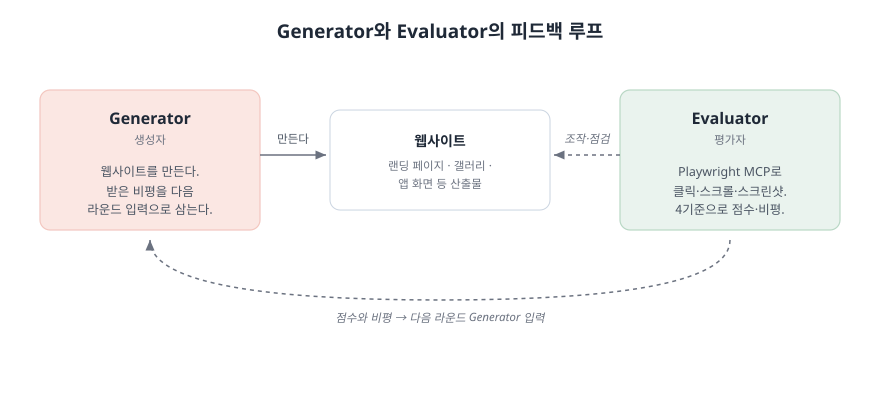 Generator와 Evaluator의 협업 루프
Generator와 Evaluator의 협업 루프
한 페이지를 만드는데 이 사이클이 5~15번 돌았고, 최대 4시간이 걸렸다고 합니다.
4.2 하네스가 만들어낸 창의적 도약
이 방식이 빚어낸 결과물 중 가장 인상적이었던 건 네덜란드 미술관 웹사이트였습니다. 9회차까지는 깔끔한 다크 테마 랜딩 페이지가 나왔습니다. 시각적으로는 잘 다듬어졌지만, 누가 봐도 예상 안의 결과물이었죠.
그런데 10회차에서 모델이 지금까지 쌓아온 접근을 통째로 버립니다. 사이트를 공간 경험으로 다시 상상한 거죠. 스크롤이나 클릭 대신 출입구를 통해 갤러리 방 사이를 이동하는 방식을 만들어냈어요. 한 번에 “만들어줘” 라고 해서 나올 수 있는 종류의 결과물이 아닙니다. 9회차까지 누적된 “이 정도로는 부족하다” 는 신호가 결국 발상을 갈아엎게 만들었습니다.
5. 앱 개발로의 확장: 3-Agent 체제
이어서 디자인 실험에서 검증된 Generator + Evaluator 협업 구조에 Planner를 추가해서, 풀스택 앱 개발에 적용했습니다.
5.1 협업 흐름
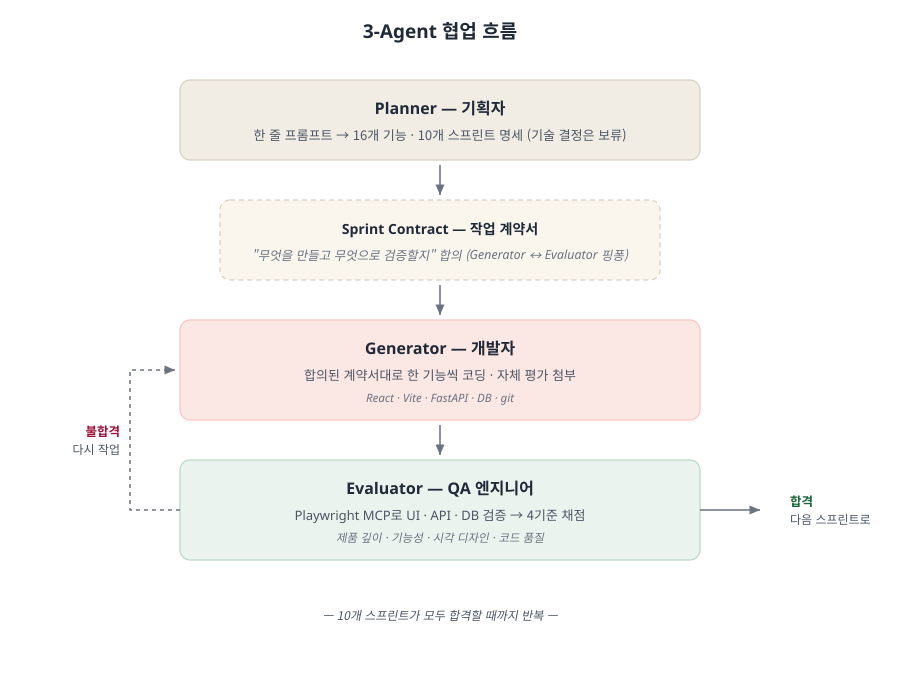
세 에이전트가 협업하는 방식은 위의 다이어그램과 같습니다.
5.2 Sprint Contract
각 스프린트가 시작되기 전에, Generator와 Evaluator는 스프린트 계약(sprint contract)을 먼저 협상합니다. 코드 한 줄을 쓰기 전에, “이번 스프린트에서 ‘완료’가 어떤 모습인가” 를 합의하는 단계입니다.
 세 역할의 팀원이 ‘완료’ 기준을 함께 맞춰가는 모습
세 역할의 팀원이 ‘완료’ 기준을 함께 맞춰가는 모습
5.3 Solo vs 3-Agent
“2D 레트로 게임 메이커를 만들어줘” 라는 한 줄짜리 프롬프트로 두 방식을 비교했습니다.
 Solo vs 3-Agent 결과 비교
Solo vs 3-Agent 결과 비교
Solo는 $\9를 버린 셈 이고, 3-Agent는 $\200어치의 프로덕션 후보 를 가져왔습니다. 3-Agent 하네스가 에이전트를 우리의 의도대로 잘 제어한 게 드러난 것입니다.
6. 모델이 발전하면 하네스는 어떻게 되는가
이 글에서 가장 흥미로운 부분입니다. 바로 모델이 발전할 때마다 하네스도 변해야 한다는 관점입니다.
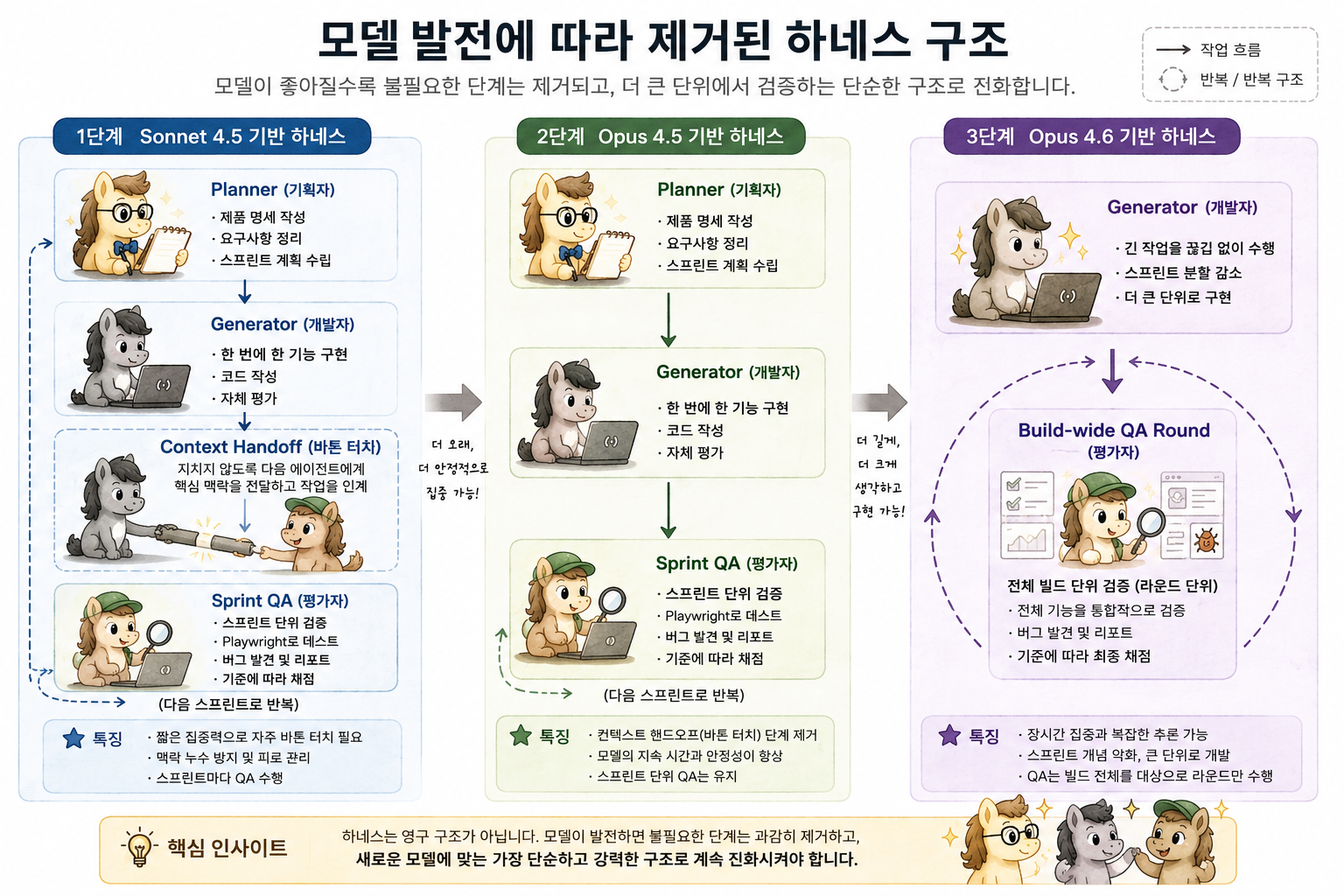 모델이 진화하면 하네스가 어떻게 변화하는지 한 눈에 알아보기
모델이 진화하면 하네스가 어떻게 변화하는지 한 눈에 알아보기
이 시점에서 Anthropic은 이런 원칙을 이야기합니다.
하네스의 모든 구성 요소는 모델이 혼자서는 안정적으로 해내지 못한다 는 가정 위에 세워진다. 그 가정은 모델이 발전하면 깨질 수 있다. 새 모델이 나올 때마다 다시 점검하고, 더 이상 필요 없어진 요소는 떼어내고, 새로 도전할 만한 영역을 위한 요소를 더해라.
개발자에게는 익숙한 과정이죠. ORM이 발전하면 raw SQL 헬퍼들이 deprecated 되고 프로젝트에서 떼어내지는 것과 같습니다. 어제까지 꼭 필요했던 보강 코드가 모델 업그레이드 한 번에 짐으로 변합니다. 떼어내지 않으면 토큰만 잡아먹고 시간만 늘리는 비용으로 남습니다.
7. 핵심 인사이트 세 가지
AI를 탐구하라: 항상 모델을 직접 실험하고, 실제 문제에서 모델의 트레이스를 분석하고, 원하는 결과를 얻을 수 있도록 튜닝해보세요. 이걸 하는 근육이 곧 에이전트와 잘 협업하는 능력을 만듭니다.
복잡한 작업은 분해하고 전문화하라: 사람의 일이 기획·구현·검수 로 분리되어 있는 데는 이유가 있습니다. 하나의 머리에 다 맡기면 어느 한 영역이 약해집니다. AI 에이전트도 똑같습니다. 기획 잘하는 에이전트, 구현 잘하는 에이전트, 검수 잘하는 에이전트를 따로 두고 협업시키면 단일 에이전트보다 결과가 분명히 좋아집니다.
하네스를 다시 점검하라: 모델이 좋아지면 지금의 하네스는 빠르게 낡을 수 있습니다. 새 모델이 나오면 하네스 구성 요소를 하나씩 제거하면서 최종 결과가 어떤 영향을 주는지 검토해보세요. 더 이상 성능의 하중을 받치지 않는 조각은 떼어네고, 이전에는 가능하지 않았던 더 큰 능력을 달성할 새 하네스 요소를 추가하세요.
마무리: 계속해서 탐구하라
원문을 닫는 한 문장이 글 전체의 결을 압축합니다.
흥미로운 하네스 조합은 모델이 발전한다고 줄어들지 않는다. AI 엔지니어의 일은 그다음 새로운 조합을 계속 찾아내는 것이다.
“AI를 잘 쓰는 기술” 의 무게중심이 프롬프트 엔지니어링에서 하네스 엔지니어링으로 옮겨가고 있습니다. 모델에게 무엇을 말하는가만큼이나 모델을 어떤 구조 안에서 돌리는가가 결과를 가르는 시대로 들어선 거죠.
그리고 그 구조는 영구적이지 않습니다. 이번에 모델이 한 단계 올라가면서 떼어낸 자리에 다음 구조가 들어섭니다. 하네스는 영원히 임시인 셈입니다. 그렇다면 우리가 가져야 할 태도는 그 다음 임시 구조를 어떻게 조합할지·무엇을 떼어낼지 계속 탐구하는 것 아닐까 싶습니다.