사용자 감정 기반 음악 추천 프로젝트 회고
1. 프로젝트 소개
- 챗봇을 통해 AI와 공감 형태의 대화를 진행하고, 그 속에서 추출된 감성분석을 통해 감성과 유사한/감성과 반대의 음악을 추천해주는 웹사이트를 제작하였습니다.
- 기획 의도 : 기존 음악어플의 플레이리스트/순위 및 장르 추천에서 벗어나 사용자의 개인 감정에 기반한 새로운 음악 추천 모델 구현
- 데이터셋
- 챗봇
- 웰니스 대화 스크립트 :
- https://aihub.or.kr/aihubdata/data/view.do?currMenu=120&topMenu=100&aihubDataSe=extrldata&dataSetSn=267
- 웰니스 대화 스크립트 :
- 감성분석
- 감성말뭉치 : https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100
- 노년층 대상 감성 분류 모델(CSV 데이터) : https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100
- 음악 추천 알고리즘
- 멜론 음악 가사 데이터(셀레니움 기반 크롤링)
- 노래별 유튜브 링크 데이터(셀레니움 기반 크롤링)
- 챗봇
팀구성 및 역할
(TEAM 음악쉼표)
- 우상욱: 웹개발(streamlit 프레임워크 활용), 챗봇 개발, ML/DL 모델링, 자연어 데이터 가공(Okt 기반 불용어처리, 토크나이징)
- 황도희: 챗봇 개발, 노래별 유튜브 링크 데이터 크롤링, ML 모델링, 자연어 데이터 가공(Okt 기반 품사추출, 토크나이징)
- 민병창: DL 모델링, 자연어 데이터 가공(subword tokenizer 기반 토크나이징), 음악 추천 알고리즘 개발
- 서영호: 자연어 데이터 가공 모델 -> 활용 데이터 적용 및 전처리, ML 모델링, ML/DL 모델 결과 비교분석
- 신제우: DL 모델링(KoBERT), 노래 가사 데이터 크롤링 및 영문-> 한글 변환 자동화 프로그램 개발
기술스택(라이브러리 위주 기술)
- 챗봇
- 데이터 가공
- PANDAS, NUMPY, TORCH
- 모델링
- SENTENCE TRANSFORMER(HUGGING FACE API)
- 데이터 가공
- 감성분석
- 데이터 가공
- PANDAS, NUMPY, KONLPY, SENTENCEPIECE
- 모델링
- SKLEARN, CATBOOST, XGBOOST, LGBM , TENSORFLOW
- 데이터 가공
- 음악 추천 알고리즘
- NUMPY, TORCH
- 웹구현
- STREAMLIT
- 데이터베이스(POSTGRESQL)
- PSYCOPG2
- 챗봇
2. 프로젝트 개요
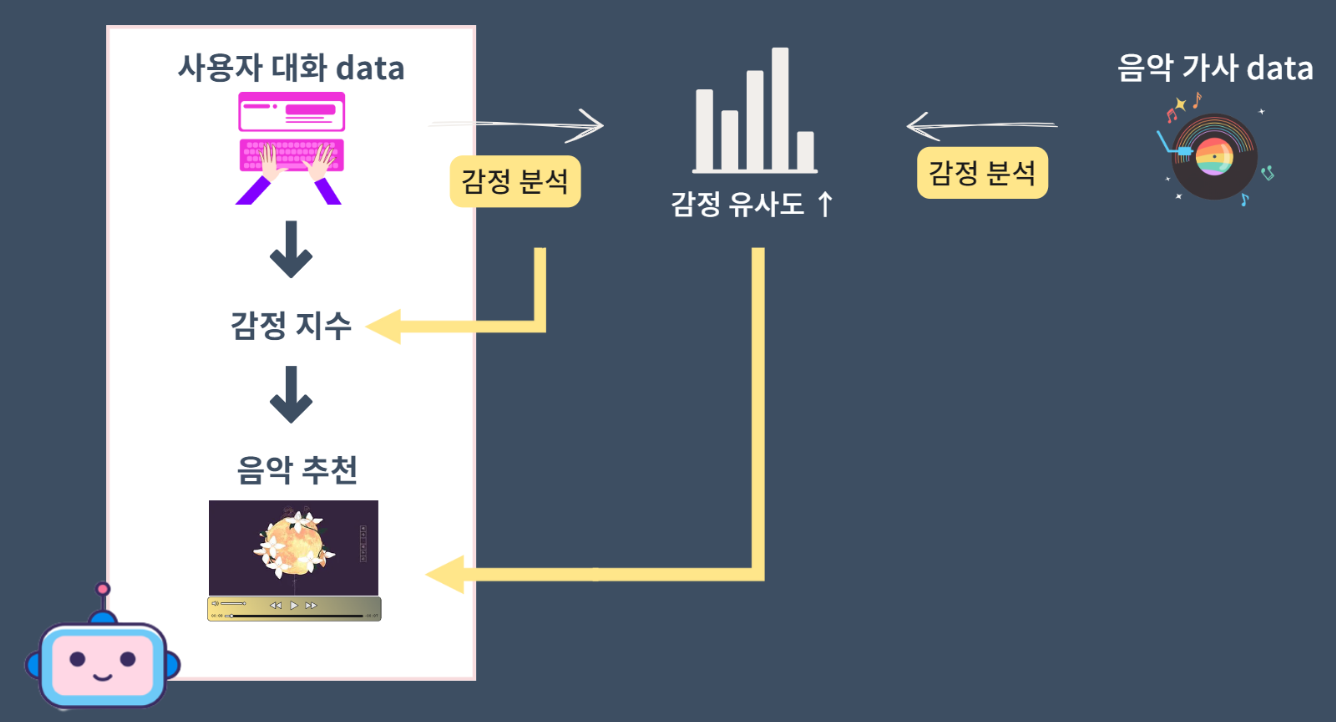
챗봇을 통해 분석된 사용자의 감성분석 데이터와, 음악 가사를 통해 분석된 감성분석 데이터의 감정 유사도를 통해 감정과 유사한 혹은 반대된 음악을 추천합니다.
2-1. 챗봇
- 심리 상담에 가장 걸맞고, 사용자의 대화에 가장 자연스럽게 응답하는 방식을 짧은 시간 내에 구현하기 위해 사전학습모델과, 코사인유사도, DB 선택법을 활용하여 챗봇을 구현하였습니다.

2-2. 감성분석 모델링
- 2가지의 전처리 방식을 활용하여 가장 스코어가 높은 모델을 찾았습니다.
- 전처리 방식
- Okt 기반 불용어처리 및 품사추출 및 구축 단어 사전 원핫인코딩
- Sentence Piece tokenizer 기반 토크나이징 데이터(vocab은 kobert 사전 활용)
- 모델링
- ML : CATBOOST, XGBOSOT, LGBM, GBM 등
- DL : LSTM, GRU, RNN 등
 OKT 기반 전처리 데이터를 활용했을 때, 일반적으로 평균 모델 성능이 좋았습니다.(KOBERT 제외)
OKT 기반 전처리 데이터를 활용했을 때, 일반적으로 평균 모델 성능이 좋았습니다.(KOBERT 제외)
2-3. 음악 추천 알고리즘

감성분석 모델을 통해 도출된 PROBA 값을 활용하여, 각 감정별로 0 ~ 1까지의 값을 가진 배열을 생성합니다. 이는 음악 데이터에도 적용되며, 챗봇을 통해 나온 데이터에도 적용됩니다.
- 기존 크롤링되어 정제된 음악 가사 데이터 약 200건
- 챗봇을 통해 나온 사용자의 텍스트
사용자의 텍스트 감정분석 데이터와 음악 가사 데이터의 감정분석 데이터를 활용하여 추천을 진행합니다.
- 감정이 비슷한 음악
- 모든 음악과 사용자의 텍스트 감정분석 데이터의 코사인 유사도를 구합니다.
- 음악의 다양성을 위해 모든 음악에 코사인 유사도 값에 랜덤으로 특정 값을 더해줍니다.
- 코사인 유사도가 가장 큰 값을 선택하여 해당 음악을 추천합니다.
- 감정이 반대인 음악
- 사용자의 텍스트 감정 분석 값이 기쁨이 가장 높을 경우
- 기쁨 값 중 절반을 가져와서, 남은 감정의 모든 데이터에 해당 값을 분포에 맞게 뿌려줍니다.
- 사용자의 텍스트 감정 분석 값이 기쁨이 가장 높지 않은 경우
- 기쁨을 제외한 나머지 감정의 절반을 전부 가져와서, 기쁨에 더해줍니다.
- 음악의 다양성을 위해 모든 음악에 코사인 유사도 값에 랜덤으로 특정 값을 더해줍니다.
- 코사인 유사도가 가장 큰 값을 선택하여 해당 음악을 추천합니다.
- 사용자의 텍스트 감정 분석 값이 기쁨이 가장 높을 경우
- 감정이 비슷한 음악
2-4. 웹구현
- 챗봇, 감성분석, 음악추천 이 파트를 웹을 통해 사용자에게 제공합니다.
(1) 챗봇
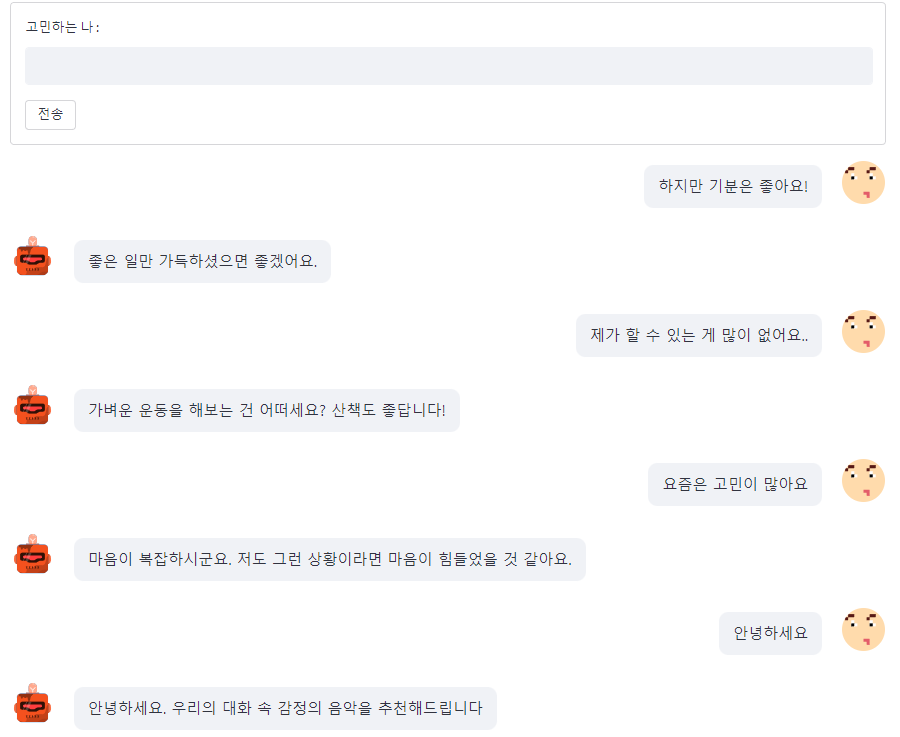
구현된 챗봇
(2) 감성분석

(3) 음악 추천
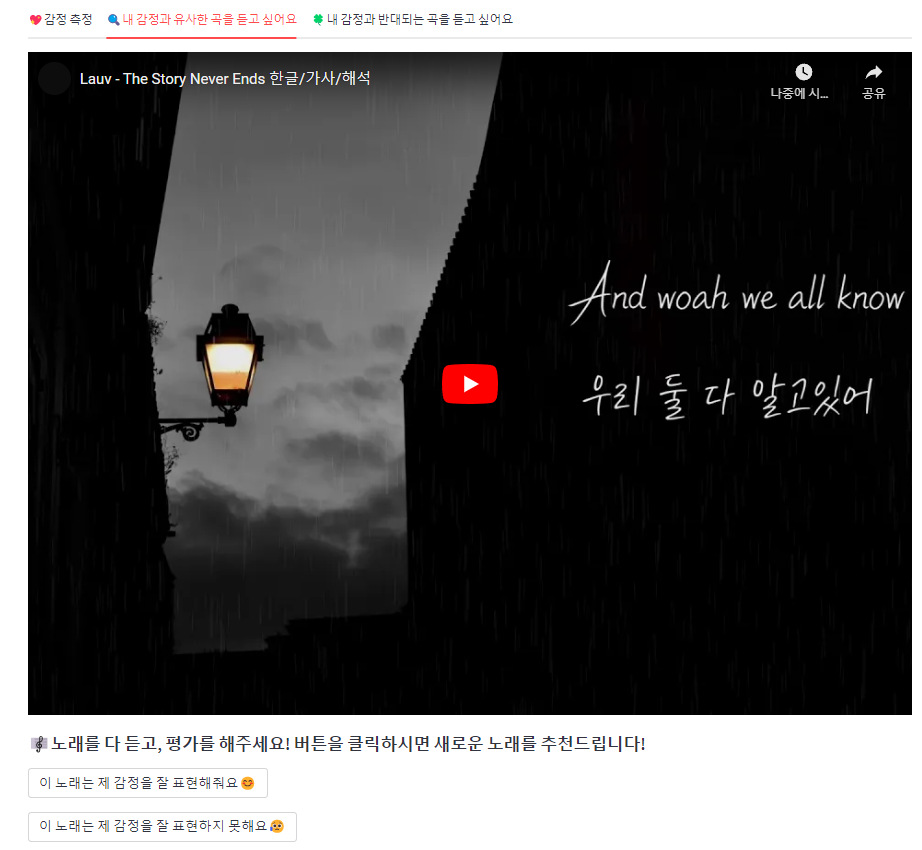
3. 프로젝트 진행 중 팀원들과의 생각과정
챗봇
- 구현은 다 된 것 같은데, 중간중간 어색한 부분이 있네.. 어떻게하면 짧은 기간에 자연스러운 대화흐름을 만들 수 있을까?
코사인 유사도 기반 자연스러운 채팅 만들기
이 부분은 사용자가 심리 상담이나 감정에 기반한 채팅을 진행하지 않았을 때 부자연스러운 흐름이 자꾸 이어졌습니다. 이에 대해서 모든 데이터에서 코사인 유사도 최대값이 특정값을 넘지 않는 경우, 가장 자연스럽게 감정에 기반한 대화를 할 수 있도록 준비한 8가지의 응답 발화를 랜덤으로 답변하게 만들었습니다. 이를 통해서 중간 중간 흐름이 자연스럽게 이어지게 할 수 있었습니다.
사용자의 공통 채팅 예상 및 데이터 추가
뿐만 아니라 사용자가 공통적으로 채팅할 수 있는 100건 정도의 데이터를 직접 발화/응답으로 나누어 데이터 셋에 추가했습니다. 직접 대답 스크립트를 만들었기 때문에 꽤나 자연스러운 채팅이 가능합니다.
감성분석
딥러닝 프로젝트인데.. 머신러닝이 점수가 더 높네.. 어떻게 하지?
저희가 만든 딥러닝 모델이, CATBOOST에 비해 과적합 및 TEST 정확도 면에서 상당히 부족했습니다. 이는 전처리 방식을 바꾸면서, 또는 토크나이저를 바꾸면서도 진행해봤습니다만, 항상 CATBOOST 모델이 더 나은 모습을 보여줬습니다. 따라서 딥러닝 프로젝트 임에도 불구하고 CATBOOST 모델을 사용했습니다. 하지만 프로젝트 막판에 KOBERT를 사용해서 학습한 모델이 기존 모델들을 제쳤습니다. 이 모델은 가지고는 있으나, 메모리 문제로 인해서 웹에는 적용하지 않았습니다.
노래의 감성을 어떻게 뽑을까..?
가사 위주로 감성을 분석하기로 했습니다. 하지만 한국 노래에도 영어가 섞인 경우가 많고, 이 부분은 노래의 영문이 섞인 부분을 한글로 번역해주는 자동화 프로그램을 개발하면서 해당 이슈는 해결했습니다. 다만 프로젝트 마무리 이후, 노래의 가사로 감성을 분석하는 것이, 언제나 노래의 감성을 대변해줄 수 없다는 점들은 팀원 모두가 공감하였습니다. 미니프로젝트가 아니였다면, 감성 뿐만이 아니라 가사의 내용과 사용자의 대화 내용이 비슷한 음악을 추천해주는 방식으로 더욱 발전시킬 수 있을 것이라 생각했습니다.
음악 추천 알고리즘
코사인 유사도로 비슷한 감정을 뽑는 건 좋아.. 그런데 반대되는 감정은?
이 부분에서 정말 많은 고민을 했습니다. 그 이유는 감정이 가장 유사한 노래를 찾는 것은 문제가 없었지만, 감정이 가장 다른 노래를 찾는 것은 감정이 극단에 있는 이상치 데이터만 찾았기 때문입니다. 이에 대해서 몇가지 안들이 나왔습니다.
- 음악 감성 분석 데이터를 기반으로 중심점을 찾아, 사용자 텍스트 감성분석 데이터 값을 중심값 기준 반대로 보낼 것
- 코사인 유사도가 가장 낮은 값으로 추천하기
- 기쁨/나머지 감정으로 분류하고 긍정과 부정 선에서 감정을 분류해볼 것 모든 부분 시도해봤으나, 결국 3번째 안이 가장 적절했습니다. 첫번째 방법과 두번째 방법은 구현이 굉장히 간단했으나, 역시 이상치 데이터를 계속 선정하는 문제가 있었습니다. 3번째 안은 구현은 간단하나, 저희가 가지고 있던 유사도 기반 약한 랜덤 추천 알고리즘에 가장 적합하기도 했습니다.
데이터베이스 활용안
좋아요 기능으로 우리가 가진 서비스를 좀 더 발전시킬 방법은 없을까?
웹에 연동된 데이터베이스를 통해서, 해당 데이터를 어떻게 활용할까 생각하고 토의했었습니다. 이 과정에서 저희는 협업 필터링 기반 추천 알고리즘을 새로 계획할 방법을 구상했습니다. 저희는 데이터베이스에 감정분석된 데이터, 추천된 노래, 그리고 유저의 좋아요/싫어요를 DB에 저장하는데, 이는 비슷한 감정을 가진 유저들의 정보를 기반으로 좋아요가 많이 찍힌 음악 위주로 추천하는 식의 발전이 가능할 것 같습니다.
챗봇.. 어떻게 뭐 자연스러운 건 알겠어. 근데, 앞으로도 계속 이렇게 8가지 문장으로 자연스럽게 대답하는 척만 할꺼야?
챗봇을 임시방편으로 자연스럽게는 만들었으나, 이 방식을 통해서 챗봇이 발전되어야한다고 생각했습니다. 따라서 저희는 데이터베이스에 코사인유사도의 최대값이 특정값을 넘지 않는 텍스트 데이터를 DB에 저장합니다. 이 방식을 통해서 유저의 공통적인 발화들은 따로 모아 데이터의 공통 질문/응답 셋을 만들어서 챗봇이 사용자가 원하는 방식으로 조금 더 업그레이드 시킬 수 있을 것이라고 생각했습니다.
한계점
아쉬운 점들이 꽤 있었습니다. 짧은 기간동안 많은 과정들을 거쳐야했고, 조금 더 나은 프로젝트를 위해 고민했던 것 같습니다.
감성기반 음악 추천 모델
모든 노래가 그 노래의 감성과 멜로디의 분위기가 같다곤 할 수 없었습니다. 따라서 기분이 울적한 사용자에 대해서, 가끔은 멜로디가 울적하지만 희망적인 가사들을 담고 있는 노래를 추천해도 제대로된 추천을 한게 맞을까?에 대한 의문이 있었습니다. 이 부분은 조금 더 깊이 들어가서, 멜로디에 대한 분류나 혹은 가사의 내용과 사용자의 대화 내용의 유사 여부까지 판단하는 과정이 필요하지 않았을까 싶습니다.
딥러닝 모델이 항상 더 좋을 것이다라는 착각
저희가 자연어를 기존에 가공한 방식은 텍스트 사전을 구축해서, 그 사전의 단어들을 기반으로 원핫인코딩을 통해 다량의 독립변수를 만들고 이를 통해 예측하는 모델이였습니다. 그런데, 이 데이터를 정형데이터 형태로 만들어놓고도, 딥러닝 모델이 성능이 더 좋을 것이다라는 착각을 하고 있었습니다. 이 과정에서 딥러닝 모델과 머신러닝 모델의 차이를 분명히 이해한 것도 맞지만, 조금 더 딥러닝 모델과 머신러닝 모델의 차이를 알고 진행했으면 어땠을까 아쉬움이 남습니다. 임베딩을 통한 자연어처리 데이터에는 딥러닝 모델을 적용하고, 원핫인코딩을 진행한 데이터에는 머신러닝을 진행하는 방식으로 했다면 조금 더 세분화된 모델링을 할 수 있었을 것 같습니다.
마무리하면서
이번 프로젝트에서는 DB를 사용해서, 테이블을 설계하고 웹에 들어오는 데이터들을 원하는 방식으로 저장하는 경험을 할 수 있었습니다. 저는 이 과정에서 웹에 있는 데이터들을 어떻게하면 서비스를 발전시키는 방향으로 데이터를 사용할 수 있을지 고민했습니다. 물론 다음 과정에서 데이터베이스를 조금 더 상세히 배우겠지만, 이 과정을 통해서 데이터를 조금 더 비즈니스를 발전시키는 방향으로 쌓고, 머신러닝 모델에 들어갈 방식으로 어떻게 데이터를 구성하는가에 대해서도 잘 배울 수 있었습니다.
아쉬운 점이 남는 프로젝트였으나, 데이터베이스의 활용과 실시간으로 데이터베이스에 넣는 방식, 그리고 테이블을 설계하는 과정에서의 고민들을 해볼 수 있다는 점에서, 데이터엔지니어로써 일하는 아주 초기단계에는 접어들지 않았나 싶습니다!!
이번 프로젝트에 대한 깃허브 주소 남깁니다:)
- 깃허브 : https://github.com/jewoodev/music_resting_place